1. 第一章 创建一个简单的解释器
这是使用 Raku 创建编译器的一章。
让我们从一个简单的解释器程序开始研究 Raku 强大的 grammar 和正则表达式,该程序可以解析并执行以下微型程序。 我将这种语言称为 Lingua。
my x;
x = 42;
say x;在理解此代码的含义时,你不会遇到任何问题,因为故意选择了类似于 Raku 本身的语法的语法,只是在变量名前没有任何符号。
该程序声明一个名为 x 的变量,为其赋一个整数值,然后将该值打印到控制台。
假设你将代码保存在文件 test.lng 中。 现在让我们使用 Raku 读取它。
my $code = 'test.lng'.IO.slurp();
say $code;将此 Raku 程序保存在另一个文件 lingua.raku 中,然后运行它:
$ raku lingua.raku如果你安装了 Raku,则会打印出我们测试程序的内容。
1.1. Grammar
现在是时候使用 Raku grammar 解析程序了。 从语法上讲,grammar 是类,但是它们使用正则表达式描述其方法的行为,这些方法又称为 rule 和 token。 第一个应用的 rule 通常称为 TOP; Raku 选择它为默认开始规则。 Grammar 用于解析某些文本,因此只需对已定义的 grammar 调用 parse 方法并将文本传递给它即可。 所有这些都在我们的第一个程序中得到了证明:
grammar Lingua {
rule TOP {
.*
}
}
my $code = 'test.lng'.IO.slurp();
my $result = Lingua.parse($code);
say $result;在这里,定义了 grammar Lingua。 它会描述我们的目标语言,目前只有一条规则,这是应用于 $code 中包含的 Lingua 代码的第一个和最后一个规则。
TOP 规则的主体是与任意行匹配的正则表达式:点与任何字符都匹配,并且星号允许重复任意数量。 TOP 方法以静默方式将正则表达式锚定在字符串的开头和结尾,因此它实际上等效于 ^.*$。
再次运行 lingua.raku,你会看到解析器设法读取了整个程序。 这是控制台中打印的内容:
「my x;
x = 42;
say x;
」这些方括号表明这打印的不是常规字符串。 在我们的例子中,$result 变量包含一个 Lingua 类的对象。
从 Lingua 程序中可以看到,其语句用分号分隔。 为了准确起见,你必须确定语句是用分号分隔还是应该以分号结尾。 区别在于,在第一种情况下,你不必在最后一条语句之后(例如,在程序末尾)加上分号。 Raku 的 grammar 允许实现这两种选项。
因此,该程序由许多用分号分隔的语句组成。 在 Raku 的 grammar 中,你可以通过以下方式表达这一点:
rule TOP {
<statement>* %% ';'
}现在,使用另一个实体, 即 statement 来描述 TOP 规则。 可以重复多次(包括不重复),并且如果有多个语句,则必须用 ';' 字符分隔。 如果你更改定义并输入 % 而不是 %%,则该规则将要求在每个语句后面必需有分号。
statement 本身是另一条规则,我们首先可以模糊地定义它:
rule statement {
<-[;]>*
}它匹配除分号字符外的所有内容。 空语句也通过此过滤器。
通过此更改,解释器现在将分割语句并发出以下输出:
「my x;
x = 42;
say x;
」
statement => 「my x」
statement => 「x = 42」
statement => 「say x」
statement => 「」第一个块显示输入程序的整个文本(所有文本均已匹配并被使用),然后显示四个单独的语句。 最后一个语句为空,因为原始文件在最后一个非空字符之后包含换行符,并且 statement 规则允许空语句。
我们的代码中有三种不同类型的语句。 它们是变量声明,赋值和调用内置函数。 可以很容易地用 grammar 表示:
rule statement {
| <variable-declaration>
| <assignment>
| <function-call>
}竖线界定规则的备选分支。 形式上,只需列出两个垂直条即可列出三个选项,但是为了使代码美观,你可以再添加一个垂直条,以使它们在代码轮廓中形成一条较长的垂直线。 如果这样做,则 grammar 不会添加空匹配项作为第一个备选分支。 顺便说一句,Raku 的另一个优点是它允许在变量和方法名中使用连字符,并且我更喜欢 variable-declaration 而不是 variable_declaration。
查看驻留在 test.lng 中的测试程序,我们可以为该 grammar 定义新规则:
rule variable-declaration {
'my' <variable-name>
}
rule assignment {
<variable-name> '=' <value>
}
rule function-call {
<function-name> <variable-name>
}带引号的字符串(例如 'my' 和 '=')将字面值与目标语言中的相应语法项进行匹配。 尖括号中的名称是对我们需要定义以完成 grammar 的其他规则或标记的引用。 这是我们的第一个标记:
token variable-name {
\w+
}它与可以组成一个单词的一系列字符匹配(因此,至少包括字母,数字和下划线)。 另请注意,变量名称中至少应包含一个字符。
rule 和 token 之间的主要区别是 Raku 处理空白的方式。 例如,看一下 variable-declaration rule 的主体:
'my' <variable-name>它使以下两个文本均合法:
my x
my x如果你创建 token 而不是 rule,则只能匹配 myx。 如你所见,grammar 中的 token 非常适合诸如变量名或关键字之类的终端。
这是 token 的另一个示例:
token value {
\d+
}在第一种方法中,我们仅将可能的值限制为非负整数。 稍后,我们将扩展 token 以包括其他类型的数字。
最后,是函数名称的标记。 到目前为止,只有一个内置函数,因此规则(在这种情况下可以是 token)很简单:
rule function-name {
'say'
}就这样。 运行程序,看看它找到了什么(我省略了重复该程序整个文本的输出的第一部分):
statement => 「my x」
variable-declaration => 「my x」
variable-name => 「x」
statement => 「x = 42」
assignment => 「x = 42」
variable-name => 「x」
value => 「42」
statement => 「say x」
function-call => 「say x」
function-name => 「say 」
variable-name => 「x」输出反映 grammar 理解的解析程序的结构。 缩进有助于查看程序及其元素的嵌套结构。 每行的右侧显示了源代码的匹配部分。
例如,程序的第一行 my x; 是一条语句,其中包含变量声明 my x 和变量名称 x。 分号被 TOP 规则的分隔符所消耗,并且没有进入输出树。 类似地,第二条语句 x = 42,是将值 42 分配给变量名 x。
如果检查第三行 say x; 生成的输出,你会看到函数名在函数名之后包含一个多余的空格:「say 」。 通过把 rule 换成 token 可以轻松解决此问题:
token function-name {
'say'
}进行此更改后,结果将更加清晰:
statement => 「say x」
function-call => 「say x」
function-name => 「say」
variable-name => 「x」1.2. Actions
目标文件现已完全解析。 我们可以将其拆分为单独的语句,并且可以理解其中的所有部分。 唯一缺少的元素是使所有这些部分协同工作以产生结果。 这就是 Raku 中的 action 要做的。
返回 Lingua 测试程序:
my x;
x = 42;
say x;要在控制台中看到 42,我们必须确保有一个存储该值的地方,并且可以通过其名称 x 进行引用。 换句话说,我们需要一个存储空间。 最明显的选择是使用哈希。 首先让我们将其设为全局变量:
my %var;
grammar Lingua {
. . .
}成功匹配 rule 或 token 后,你可以要求 Raku 为你做点事情,即,你可以添加一个叫做 action 的代码块,该代码块将在匹配后执行。 在其中,你可以访问刚刚提取的数据。
我们的第一个 action 是在看到变量声明时创建一个变量。 这是你的操作方式:
rule variable-declaration {
'my' <variable-name> {
%var{$<variable-name>} = 0;
}
}将 action 放在一对花括号中的正则表达式之后。 我们知道,该规则通过匹配字面值 'my' 和变量名来找到子字符串 my x,变量名是命名 token variable-name。 我们可以使用该名称访问内容:$<variable-name>。 实际上,这是 Lingua 类的对象,但是我们将其用作哈希的键,因此将其转换为字符串,并使用新的对 x ⇒ 0 填充哈希。因此, 创建并用零初始化。
同样,让我们为变量复制创建一个 action。
rule assignment {
<variable-name> '=' <value> {
%var{~$<variable-name>} = +$<value>;
}
}在这里,为了说明你也可以做到这一点,将 $<variable-name> 对象通过 ~ 前缀运算符显式转换为 Str 数据类型的值。 在等号的右侧,完成了另一种类型转换:+ 运算符将 $<value> 转换为数字。 这次,强制转换值非常重要,因为如果你不这样做,将保存一个 Lingua 对象而不是数字。
现在转到函数调用。
rule function-call {
<function-name> <variable-name> {
say %var{$<variable-name>}
if $<function-name> eq 'say';
}
}say 函数的实现嵌入在 grammar 的 action 中。 由于我们现在只有一个内置函数,因此实际上不需要 if 子句,但是让我们保留它可以使代码更透明。
到目前为止,这三个 action 块是内联的。 它们是规则定义的一部分。 我们可以运行解释器并查看其作用。 将主代码更改为以下代码,以避免大量输出:
my $code = 'test.lng'.IO.slurp();
my $result = Lingua.parse($code);
#say $result;这段代码打印出如下行:
$ raku lingua.raku
42恭喜你! 该程序不仅被解析而且还被执行。 如你所见,它打印了变量 x 的内容,这正是我们放入变量 x 中的内容。 如果你转储 %var 容器(通过添加 say %var;),则会得到 {x ⇒ 42}。
这是我们第一个真正的成就。 我们设法为将来的 Lingua 语言的子集创建了一个解释器。 这里最令人兴奋的部分是它没有绑定到我们之前使用的单个测试程序。 你可以根据需要创建任意多个变量,可以将其分配给不同的值,然后再次重新分配它们。 变量名比单个字母长。 所有这些神奇地起作用! 自己尝试一下,这是我所做的一个示例:
my alpha;
my beta;
alpha = 100;
beta = 200;
say alpha;
say beta;
my gamma;
gamma = 33;
say gamma;
gamma = 44;
say gamma;执行后,程序将打印正确的结果:
100
200
33
44你也可以尝试多次给 value 赋值:
my value;
value = 100;
say value;
value = 200;
say value;这次,该程序两次使用相同的变量并在其中存储了不同的值,你可以通过运行该程序轻松确认:
100
2001.3. 模块
第一个简单的解释器已经准备就绪,但让我们多花点时间使它的代码更加结构化并且更快。
首先,可以将内联 action 收集在单独的类中。 在我们当前的实现中,所有 action 都是单行的,但是在更高级的编译器中,情况并非如此。 在 Raku 中,表达 action 和 grammar 规则之间的关系非常容易:在创建 action 类的方法时,只需使用相同的名称即可。 查看以下代码,你就马上理解了。
class LinguaActions {
method variable-declaration($/) {
%var{$<variable-name>} = 0;
}
method assignment($/) {
%var{~$<variable-name>} = +$<value>;
}
method function-call($/) {
say %var{$<variable-name>}
if $<function-name> eq 'say';
}
}所有这些方法都接收一个参数。 参数名可以是你想要的任何名称,但为方便起见,最好将其命名为 $/,因为在这种情况下,可以使用 $<value> 之类的快捷方式代替 $/<value>。 如果你将其命名为 $arg,则必须输入更多字符才能访问其部分:$arg<value>。 另外,别忘了从 grammar 类中删除代码块及其周围的花括号。
要将 action 类与 grammar 一起使用,请将其作为命名参数传递给 parse 方法:
Lingua.parse($code, :actions(LinguaActions));提取类并将它们保存在单独的文件中也是一种好习惯。 例如,把 grammar 放入 Lingua.rakumod,把 action(连同 %var 哈希,目前是模块的全局变量)放入 LinguaActions.rakumod 中。 整个解释器代码将缩短为以下内容:
use Lingua;
use LinguaActions;
my $code = 'test.lng'.IO.slurp();
Lingua.parse($code, :actions(LinguaActions));此步骤不仅有助于逻辑上组织代码,而且可以提高解释速度。 如果 Raku 编译器能够缓存已编译的模块,则只需要编译一次即可。 每次下一次运行都更快,因为使用了模块的预编译版本。
2. 第二章 解析数字
在接下来的两章中,我们将暂时保留上一章中创建的编译器,并将使用一个单独的助手程序,即计算器。 它本身是一件有趣的事情,我们将在一个孤立的示例中对其进行探索。 在下一章中,它将集成到解释器中。
2.1. 查找数字
计算器可以处理数字,因此我们要做的第一件事就是做一个用于解析数字的解析器。 在上一章中,我们仅使用非负整数,但是好的计算器必须理解更多的数字格式。 例如,它包括负数和浮点数,也可以用科学计数法表示。 我们还必须允许人们省略小数点前面的零并输入 .5 而不是 0.5 的情况。
让我们为不同类型的数字迭代创建解析器。 由于我们将对 grammar 进行大量更改,因此提供了一个测试套件来进行救援。
my @cases = 7, 77, -84;
for @cases -> $number {
say "Test $number";
say Number.parse($number);
}@cases 数组包含将针对 Number grammar 进行测试的数字列表。 这是它的第一个版本:
grammar Number {
rule TOP {
<number>
}
token number {
\d+
}
}整个 grammar 需要一个数字,即一个数字序列。 它可以与我们当前的测试用例一起使用,并且程序的输出是可以预测的:
Test 7
「7」
number => 「7」
Test 77
「77」
number => 「77」
Test -84
Nil前两个数字通过了测试,但第三个没有通过。 对于负数,parse 方法返回 Nil。
因此,我们需要扩展 number 标记并在数字前面添加可选的减号。 重要的是,它仍然必须是 token,因为你通常不希望符号和数字之间有空格。
token number {
'-'? \d+
}这个很小的变化使另一半整数, 即负整数, 变得合法。 以上测试现在将通过。
Test -84
「-84」
number => 「-84」但是,如果你将正数拼写为 +7 会怎么样?
my @cases = 7, 77, -84, '+7', 0;Grammar 解析器始终消费字符串,但是我们可以让 Raku 转换诸如 7 或 77 之类的正数,以避免在测试用例列表中额外的引号。以 +7 为例, 我们必须保留加号, 所以该测试用例是一个显式的字符串。
根据 grammar,此数字不是有效数字。 因为它期望整个字符串是一个数字,所以我们不能期望加号会被简单地忽略掉。 解析器需要在开始时就知道可能的符号,因此,我们需要将其添加到 token 主体中:
token number {
<[+-]>? \d+
}让我们也减少输出中的噪声,并且不打印解析树:
for @cases -> $number {
my $test = Number.parse($number);
say ($test ?? 'OK ' !! 'NOT OK ') ~ $number;
}现在,输出与在测试 Perl 和 Raku 模块中广泛使用的 TAP(任何测试协议)部分兼容。
OK 7
OK 77
OK -84
OK +7
OK 0添加一个无效的数字,你会立即看到它失败,例如:
NOT OK 3.14实现浮点数解析器的第一次尝试可以像这样简单:
token number {
<[+-]>? \d+ ['.' \d+]?
}我们只是添加了一个可选的小数部分。 但是,如果遇到一个有点但没有整数部分的数字怎么办? 它不会通过测试,但是可以通过将正则表达式左侧的 \d+ 更改为 \d* 来轻松解决:
token number {
<[+-]>? \d* ['.' \d+]?
}不幸的是,此更改破坏了该 token,因为它可以应用于单个符号,甚至可以应用于空字符串。 现在所有这些测试用例都是 OK 的:
my @cases =
7, 77, -84, '+7', 0,
3.14, -2.78, 5.0, '.5',
'', '-', '+';尝试在单个正则表达式中表达所有选项有点棘手。 显式列出所有备选分支要容易得多。 我们知道符号可以出现在任何数字的前面,让我们将备选分支放在方括号中:
token number {
<[+-]>? [
| \d+
| \d* ['.' \d+]
]
}这种方法使整个 tokenn 更具可读性和可扩展性。 我们可以添加另一种备选分支来匹配科学计数法中的数字。
token number {
<[+-]>? [
| \d+
| \d* ['.' \d+]
| \d+ <[eE]> <[+-]>? \d+
]
}现在有更多测试用例通过了该 grammar:
'3E4', '-33E55', '3E-3', '-1E-2'我们所缺少的是科学计数法中带有非整数小数部分的数字,例如 3.14E2 或 .5E-3。 另一种备选分支可以解决此问题:
token number {
<[+-]>? [
| \d+
| \d* ['.' \d+]
| \d+ <[eE]> <[+-]>? \d+
| \d* ['.' \d+] <[eE]> <[+-]>? \d+
]
}在这种形式中,有些部分会重复,例如 \d+ 或 \d* ['.' \d+]。 在这种紧凑的规则中可能会很好,但是也可以对其进行进一步分解,并引入负责此类重复部分的子 token。 转换后的 number token 及其家族如下所示:
token number {
<sign>? [
| <integer>
| <floating-point>
| <integer> <exponent>
| <floating-point> <exponent>
]
}
token sign {
<[+-]>
}
token exp {
<[eE]>
}
token integer {
\d+
}
token floating-point {
\d* ['.' <integer>]
}
token exponent {
<exp> <sign>? <integer>
}尽管与以前的版本相比有更多的代码,但每个单独的 token 都更易于理解。 例如,先前和当前以科学记数形式表示的数字,其小数部分是浮点数。 之前是:
\d* ['.' \d+] <[eE]> <[+-]>? \d+转换后,它变成:
<floating-point> <exponent>看一下主 token 的备选分支,
| <integer>
| <floating-point>
| <integer> <exponent>
| <floating-point> <exponent>你会立即看到他们的描述。 甚至,我们可以进一步化简它:
token number {
<sign>? [
| <integer>
| <floating-point>
] <exponent>?
}换句话说,数字可以是整数,也可以是浮点值,其后跟一个可选的符号,然后可以跟一个可选的指数部分。 以这种形式,描述是如此简洁和紧凑。 所有细节(正则表达式"噪声")都隐藏在辅助 token 标记中。
2.2. 获取值
该数字已解析,但是它的值是什么? 对于编译器,我们不仅需要检查数字格式的有效性,还需要将其从字符串转换为数字,整数或浮点数。 在本节中,我们将在 Number grammar 后面添加 action,以便我们可以构建数字并最终打印出来。
让我们以整数开头,并将数字保留在全局变量中。
my $n = 0;
class NumberActions {
method integer($/) {
$n = +$/;
}
}这里的一切看起来都很简单。 通过使用 + 前缀运算符将字符串的匹配部分转换为数字值,可以直接得出整数值。 要查看其工作原理,让我们更改主测试循环,以使其输出已解析的值:
for @cases -> $number {
my $test = Number.parse($number, :actions(NumberActions));
if ($test) {
say "OK $number = $n";
}
else {
say "NOT OK $number";
}
}使用非负整数,效果很好:
OK 7 = 7
OK 77 = 77
OK -84 = 84
OK +7 = 7
OK 0 = 0负数无效。 看来 +7 字符串已被正确处理,但实际上这并不完全正确,因为我们完全忽略了该符号。 这次,任务有点复杂。 第一个想法是,如果遇到减号,则翻转符号:
method sign($/) {
$n *= -1 if ~$/ eq '-';
}但是,这是行不通的,因为符号是在解析数字之前先解析的,而否定 $n 意味着将符号应用于零。 我们可以使用一个单独的变量来保留有关标志的信息,但这并不是最好的选择。 但是,请这样做,因为这将引出另一个问题。
my $n = 0;
my $sign = 1;
class NumberActions {
method integer($/) {
$n = $sign * +$/;
}
method sign($/) {
$sign = -1 if ~$/ eq '-';
}
}这有助于检测第一个负数,但会破坏所有其他负数。 当然,你可以检查符号是否为 '+',但问题是 $n 和 $sign 变量是全局变量,必须在解析下一个变量之前将其重置。 这是将它们移至 action 类的好时机。
class NumberActions {
has $.n = 0;
has $!sign = 1;
method integer($/) {
$!n = $!sign * +$/;
}
method sign($/) {
$!sign = -1 if ~$/ eq '-';
}
}$n 变量有意成为公共数据成员,因为我们必须以某种方式获得结果。 你还需要更改测试循环。
for @cases -> $number {
my $actions = NumberActions.new();
my $test = Number.parse($number, :actions($actions));
if ($test) {
say "OK $number = " ~ $actions.n;
}
else {
say "NOT OK $number";
}
}此处的主要更改是将 NumberActions 类的实例传递给 grammar 的 parse 方法。 现在,在每次迭代中,解析器都会创建自己的变量以保留结果。
我们已经走了足够远的距离,以至于可以正确解析所有整数:
OK 7 = 7
OK 77 = 77
OK -84 = -84
OK +7 = 7
OK 0 = 0对于浮点数,它的工作不那么顺畅:
OK 3.14 = 14
OK -2.78 = -78
OK 5.0 = 0
OK .5 = 5
OK -5.3 = -3
OK -.3 = -3
OK 3E4 = 4
OK -33E55 = -55
OK 3E-3 = -3
OK 3.14E2 = 2
OK .5E-3 = -3如你所见,小数部分或指数部分均获胜。 在两种情况下,这都是 grammar 的最后一个整数部分。 确实,早些时候,我们对 grammar 进行了转换,以排除重复部分。 当我们不得不引入 $sign 变量时,钟声响了,但现在我们遭受的痛苦更大。 所有这些都需要以不同的方式处理。 这就是 AST 可以提供帮助的方式。
2.3. 使用 AST
AST,或抽象语法树,是一种允许在不同阶段收集和保持数据解析的机制。 如果在读取浮点数 3.14 时两次调用了 integer token,或者对带有指数的数字(例如 3.14E2)调用了三次,则所有这些整数都可以保留在 AST 中,并在以后用于构建整数。 对应于整个字符串的值。
在 action 类的方法内,$/ 变量有两种方法:make 和 made。 使用 make 可以存储一个值(将属性分配给解析树的当前节点)。 使用 made 时,你将读取先前存储的值。
将以下调用添加到 token action 中:
method integer($/) {
$/.make(+$/);
}
method sign($/) {
$/.make(~$/ eq '-' ?? -1 !! 1);
}现在,即使多次调用该方法,也将保存这些值。 要了解它是如何工作的,让我们看一下 grammar 对象:
my $test = Number.parse($number, :actions($actions));
dd $test;dd 例程是 Rakudo 专用的工具,可显示对象的内部结构。 对于输入数字 -84,解析后将构建以下对象:
Number $test = Match.new(list => (), hash => Map.new((:number(Match.new(list => (), hash => Map.new((:integer(Match.new(list => (), hash => Map.new(()), made => 84, orig => -84, pos => 3, from => 1)),:sign(Match.new(list => (), hash => Map.new(()), made => -1, orig => -84, pos => 1, from => 0)))), made => Any, orig => -84, pos => 3, from => 0)))), made => Any, orig => -84, pos => 3, from => 0)看起来很凌乱,但你应该可以发现我们最感兴趣的两个地方:
made => 84, orig => -84, pos => 3, from => 1
made => -1, orig => -84, pos => 1, from => 0将 from 和 pos 键设置为指向第一个字符以及与正则表达式匹配的最后一个字符之后的字符。 因此,这两个子哈希中的第一个是解析数字的结果(字符串’-84'` 中从位置 1 到位置 3,即 84)。 第二个哈希对应减号字符(同一字符串中的位置0到1)。
made 属性分别设置为 84 和 -1,这确认 grammar 能够正确解析数字及其符号。
现在可以使用这些值在父标记中生成结果。
method number($/) {
my $n = $<integer>.made;
$n *= $<sign>.made if $<sign>;
$/.make($n);
}它通过 $<integer> 和 $<sign> 对象的 made 属性访问整数值和符号乘号。 最后一行将结果传递到下一个级别,你可以从 TOP 规则中访问它:
method TOP($/) {
$/.make($<number>.made);
}对于当前的解析数字任务,可以将 TOP 规则和方法完全替换为 number token 和 action 方法的内容(请注意,TOP 现在是 token,而不是 rule):
grammar Number {
token TOP {
<sign>? [
| <integer>
| <floating-point>
] <exponent>?
}
. . .
}
class NumberActions {
method TOP($/) {
my $n = $<integer>.made;
$n *= $<sign>.made if $<sign>;
$/.make($n);
}
. . .
}如果查看由 parse 方法返回的对象,你将看到它包含以下字段:
from => 0, orig => -84, made => -84, pos => 3made 的值包含我们所需的负整数。 可以使用相同的属性从 grammar 外部和 action 外部进行访问:
my $test = Number.parse($number, :actions($actions));
if ($test) {
say "OK $number = " ~ $test.made;
}任务已完成,我们可以继续处理带有指数部分的整数。 例如 3E4。 使用这样的数字,integer token 被触发两次,但这并不成问题,因为两个整数都位于不同对象的相应的 made 属性中。
创建一个 action 以处理指数部分:
method exponent($/) {
my $e = $<integer>;
$e *= -1 if $<sign> && ~$<sign> eq '-';
$/.make($e);
}并使用该值乘以数字:
method TOP($/) {
my $n = $<integer>.made;
$n *= $<sign>.made if $<sign>;
$n *= 10 ** $<exponent>.made if $<exponent>;
$/.make($n);
}运行测试套件,并检查它对于 3E4 或 -1E-2 这样的数字产生什么:
OK 3E4 = 30000
OK -33E55 =
-330000000000000000000000000000000000000000000000000000000
OK 3E-3 = 0.003
OK -1E-2 = -0.01目前,唯一没有关联 action 的 token 是浮点数。 (exp token 不需要任何 token,因为它的唯一任务是与 e 或 E 匹配)。 让我们再来看一次:
token floating-point {
\d* ['.' <integer>]
}创建 token 时,我们用 <integer> 替换了 \d+ 部分。 实际上,一个可选序列 \d* 也可以替换为:
token floating-point {
<integer>? ['.' <integer>]
}现在,同一 token 中有两个 <integer> 调用! 在这种情况下,你在 action 中写了什么? 很简单:如果多次提到该名称,你将获得一个数组,因此可以将第一个匹配项引用为 $<integer>[0],将 $<integer>[1] 引用为第二个匹配项。
唯一的问题是,在我们的情况下,第一个整数部分是可选的。 如果你解析 3.14,则会获得两个元素,但是如果你解析了 .14,则 14 将到达索引为 0 的元素。可能的解决方案之一就是检查数组的长度。 求值是一项相对简单的任务。
method floating-point($/) {
my $int = 0;
my $frac = 0;
if $<integer>.elems == 2 {
($int, $frac) = $<integer>;
}
else {
$frac = $<integer>[0];
}
my $n = $int + $frac / 10 ** $frac.chars;
$/.make($n);
}如果解析了 TOP token,则还必须更新它以获取浮点数的值:
my $n = $<integer> ??
$<integer>.made !! $<floating-point>.made;任务似乎已经解决。 所有数字(包括带小数点和指数部分的数字)均已成功处理:
OK 3.14 = 3.14
OK -2.78 = -2.78
OK 5.0 = 5
OK .5 = 0.5
OK -5.3 = -5.3
OK -.3 = -0.3
OK 3E-3 = 0.003
OK -1E-2 = -0.01
OK 3.14E2 = 314
OK .5E-3 = 0.00052.4. 最后的笔记
在本章中,我们设法将字符串转换为数字,但是它们是哪种数字? 为了获得数字,我们使用了 Raku 中可用的运算符,例如二元运算符 +,算术运算符和幂运算符 **。 使用所有这些的计算结果是一个数字,该数字是 Raku 提供的一种数字类型的实例。
你可以通过在测试循环中显式打印类名称来看到它:
say "OK $number = " ~ $test.made ~
' (' ~ $test.made.^name ~ ')';所有不包含小数点的数字均为 Int,其余均为 Rat:
OK 7 = 7 (Int)
OK 77 = 77 (Int)
OK -84 = -84 (Int)
OK +7 = 7 (Int)
OK 0 = 0 (Int)
OK 3.14 = 3.14 (Rat)
OK -2.78 = -2.78 (Rat)
OK 5.0 = 5 (Rat)
OK .5 = 0.5 (Rat)
OK -5.3 = -5.3 (Rat)
OK -.3 = -0.3 (Rat)
OK 3E4 = 30000 (Int)
OK -33E55 = -330000000000000000000000000000000000000000000000000000000 (Int)
OK 3E-3 = 0.003 (Rat)
OK -1E-2 = -0.01 (Rat)
OK 3.14E2 = 314 (Rat)
OK .5E-3 = 0.0005 (Rat)现在,再次查看 action 类中的 floating-point 方法。 尽管其算法简单明了,并且可以产生正确的结果,但是它比较啰嗦,需要几行代码。 另外,你可以将此任务传递给宿主语言本身! 让 Raku 为你解析浮点数:
my $n = +"$int.$frac";
$/.make($n);等待,什么是 "$int.$frac"? 它是一个在解析过程中与 floating-point token 匹配的字符串,这意味着与其重建字符串并将其转换为数字,我们还可以直接将 $/ 对象转换为数字,而无需访问它:
method floating-point($/) {
$/.make(+$/);
}该代码是否类似于你已经看到的内容? 此方法的主体与 integer 方法的主体完全相同:
method integer($/) {
$/.make(+$/);
}确实,当 Raku 仅包含数字时,我们允许它为我们建立数字。 如果我们也遇到带小数点的数字,则可以再次代理它。
但这还不是全部。 我们的 Number grammar 允许的数字都是有效的 Raku 数字,并且可以用一行代码替换我们所有的 action:
class NumberActions {
method TOP($/) {
$/.make(+$/);
}
}更改之后,数字的类型略有不同。 Raku 在科学计数法中将数字视为 Num,而不是 Rat。 你可以通过再次运行测试循环来确认:
OK 7 = 7 (Int)
OK 77 = 77 (Int)
OK -84 = -84 (Int)
OK +7 = 7 (Int)
OK 0 = 0 (Int)
OK 3.14 = 3.14 (Rat)
OK -2.78 = -2.78 (Rat)
OK 5.0 = 5 (Rat)
OK .5 = 0.5 (Rat)
OK -5.3 = -5.3 (Rat)
OK -.3 = -0.3 (Rat)
OK 3E4 = 30000 (Num)
OK -33E55 = -3.3e+56 (Num)
OK 3E-3 = 0.003 (Num)
OK -1E-2 = -0.01 (Num)
OK 3.14E2 = 314 (Num)
OK .5E-3 = 0.0005 (Num)这里的输出格式还取决于 Raku 如何打印不同数字类型的数字。
在此特定任务中,我们所有的体力劳动都由宿主语言中的编译器 action 代替。 当然,这是有可能的,因为我们选择了许多编程语言都可以处理的标准数据格式。 一旦发现解决问题的简单方法,不要害怕删除自己的代码。 本章中介绍的使用 AST 的技术是本书未来冒险的基础。 敬请关注!
P. S.细心的读者可能已经注意到,Number grammar 不包含数字(例如`4.`),其中有整数部分,小数点但没有小数部分。 这些数字在 Raku 本身中是不允许的,因此我没有将其包括在 grammar 中。
3. 第三章 创建计算器
在本章中,我们将创建一个程序,该程序可以评估简单的算术表达式,例如 3 + 4 或 3 - 3 * 7。我们将从具有两个操作数的最简单方程式开始,一直工作到引入括号。
3.1. 汇总
让我们首先获取一个测试表达式 3 + 4 并为此创建一个可工作的计算器原型。 语法只需要解析整数和文字加号:
grammar Calculator {
rule TOP {
<number> '+' <number>
}
token number {
\d+
}
}动作也很简单。 我们正在使用 AST 属性来保留值:
class CalculatorActions {
method TOP($/) {
$/.make($<number>[0].made + $<number>[1].made);
}
method number($/) {
$/.make(+$/);
}
}一切准备就绪,可以运行测试并确认它确实打印 7:
Calculator.parse('3 + 4',
:actions(CalculatorActions)).made.say;这一点都不困难。 该代码可与其他整数一起使用,而语法或动作没有变化,但是我们的下一个目标是教它处理-进行减法。
第一种方法可以在语法的最顶部引入不同类型的语句:
rule TOP {
| <addition>
| <subtraction>
}
rule addition {
<number> '+' <number>
}
rule subtraction {
<number> '-' <number>
}因此,让我们为加法和减法创建单独的操作方法:
method TOP($/) {
$/.make($<addition> ??
$<addition>.made !! $<subtraction>.made);
}
method addition($/) {
$/.make($<number>[0].made + $<number>[1].made);
}
method subtraction($/) {
$/.make($<number>[0].made - $<number>[1].made);
}现在,测试第二种情况:
my @cases = '3 + 4', '3 - 4';
for @cases -> $test {
say "$test = " ~ Calculator.parse($test,
:actions(CalculatorActions)).made;
}好的,一切都按预期进行:
3 + 4 = 7
3 - 4 = -1一切正常,但是你不应该对解决方案感到满意。 最好将加法和减法合并为一个规则:
rule TOP {
<number> <op> <number>
}
token op {
'+' | '-'
}语法变得更简单,并且运算符在其自己的与加号或减号匹配的标记中明确定义。
同样,加法和减法动作方法可以用通用解决方案代替:
method TOP($/) {
if $<op> eq '+' {
$/.make($<number>[0].made + $<number>[1].made);
}
else {
$/.make($<number>[0].made - $<number>[1].made);
}
}就是这样。 更新后的语法将两个测试字符串都视为有效表达式,并根据 $<op> 的内容进行正确的计算。 当检查 $<op> eq '+' 中的条件时,eq 字符串比较运算符将 $<op> 隐式转换为字符串,并且不需要单独的操作来处理 op 令牌。
3.2. 过早的优化
有什么方法可以使代码更具吸引力? 有几个。 我们将尝试两种方法来统一通话。 目的是避免重复长的代码行,唯一的区别是操作的符号,例如:
$/.make($<number>[0].made - $<number>[1].made);在这两种情况下,运算符都被相同的两个操作数包围,这是编写几个双函数的好机会:
class CalculatorActions {
sub addition($a, $b) {
$a + $b
}
sub subtraction($a, $b) {
$a - $b
}
. . .
}这两个函数都可以放置在 CalculatorActions 类内部,并且当调用它们时,Raku 不会将指向该类实例的其他参数传递给它。 为了为这两个函数建立共同的入口点,让我们创建一个保留对它们的引用的哈希:
class CalculatorActions {
my %operation =
'+' => &addition,
'-' => &subtraction;
. . .
}根据运算符调用函数非常容易:
method TOP($/) {
$/.make(%operation{~$<op>}(
$<number>[0].made, $<number>[1].made));
}简化代码并摆脱显式检查(如果检查)的另一个有趣选择是使用多个分派。
class CalculatorActions {
multi sub operation('+', $a, $b) {
$a + $b
}
multi sub operation('-', $a, $b) {
$a - $b
}
method TOP($/) {
$/.make(operation(~$<op>,
$<number>[0].made,
$<number>[1].made));
}
. . .
}在这里,运算符被传递给操作函数,编译器选择要调用的候选对象:用加号定义的操作或需要减号作为其第一个参数的操作。 Raku 编译器很高兴为我们完成了这项工作。
3.3. 更多操作数
语法和动作现在已经足够聪明,可以解析和评估其中具有两个值的表达式,但不适用于 1 + 2 + 3 等更复杂的示例。由于TOP级别受规则限制,因此无法使用 仅两个数字:<number> <op> <number>。
在语法中,链中新的可选项目可以用 * 量词表示:
rule TOP {
<number> [<op> <number> <ws>]*
}<ws> 令牌是用于匹配可选空格的内置工具。 通过此更改,我们还允许包含单个数字的表达式。 因此,以下测试用例全部匹配:
my @cases =
'3 + 4', '3 - 4',
'7',
'1 + 2 + 3', '1 + 3 + 5 + 7';进行真实计算的两个函数还必须适用于接受两个以上的值:
multi sub operation('+', @values) {
[+] @values
}
multi sub operation('-', @values) {
[-] @values
}此时,使用归约运算可大大简化语法。 最后,准备一个值数组,以将其传递给以下多功能之一:
method TOP($/) {
$/.make(operation(~$<op>[0], $<number>.map: *.made));
}为了从 AS T树中获取数字,此处使用 map 方法。 *.made 结构是对 $<number> 数组的每个元素执行的 WhateverCode 块。
正如我们已经预期的那样,计算器必须使用单个数字,因此需要一个小的扩展名。 只有一个数字,表达式中没有运算符:
method TOP($/) {
if $<op> {
$/.make(operation(~$<op>[0], $<number>.map: *.made));
}
else {
$/.make($<number>[0].made);
}
}运行测试并检查是否正确评估了所有测试用例:
3 + 4 = 7
3 - 4 = -1
7 = 7
1 + 2 + 3 = 6
1 + 3 + 5 + 7 = 163.4. 多样性测试
运算符(例如[+])的简化形式的优美和简单性使得可以用几个字符表示动作,但无法用 7 + 8 - 3 等不同的运算符来评估表达式。 为了处理这样的示例,可以组织一个遍历运算符和操作数的循环。
在顶层,你必须遍历所有数字,然后将运算符带到旁边。 这是一个如何遍历值的示例:
method TOP($/) {
my @numbers = $<number>.map: *.made;
my $make = @numbers.shift;
operation(~$<op>.shift, $make, @numbers.shift)
while @numbers.elems;
$/.make($make);
}为了简化 while 循环,让操作多功能更新其参数之一:
multi sub operation('+', $a is rw, $b) {
$a += $b
}
multi sub operation('-', $a is rw, $b) {
$a -= $b
}同样,代码看起来紧凑,更重要的是,它可以正常工作。
7 + 8 - 3 = 12
14 - 4 = 10
14 - 4 - 3 = 7
100 - 200 + 300 + 1 - 2 = 1993.5. 增加更多数学
计算器现在仅能进行加减运算。 好处是它可以计算包含两个以上数字的长表达式。 现在是时候教它处理乘法和除法了。
仅扩展 op 令牌以创建更多的操作函数候选者是天真的:
grammar Calculator {
. . .
token op {
'+' | '-' | '*' | '/'
}
. . .
}
class CalculatorActions {
. . .
multi sub operation('*', $a is rw, $b) {
$a *= $b
}
multi sub operation('/', $a is rw, $b) {
$a /= $b
}
. . .
}该语法使用全部四个算术运算来解析甚至评估所有可能的表达式,但是它不遵循标准的优先级规则:
3 * 4 = 12
100 / 25 = 4
1 + 2 * 3 = 9可能的解决方案之一是使用堆栈来执行计算。 你从左到右扫描输入字符串,并继续将下一个运算符应用于数字,直到遇到优先级更高的运算符为止。 在这种情况下,你将当前结果放入堆栈,并继续进行一系列新的计算,直到找到优先级较低的运算符。 然后,从堆栈中弹出数字和运算符,并将其减少,直到完全消耗掉为止。 这是在家中进行的好练习,但是我们将选择一种简单的方法。
处理算术运算优先级的另一种方法是更改语法,以使其首先提取乘法和除法运算,然后将结果传递给其余的加法和减法。
在下一个片段中,显示新语法:
grammar Calculator {
rule TOP {
<term>* %% <op1>
}
rule term {
<factor>* %% <op2>
}
token op1 {
'+' | '-'
}
token op2 {
'*' | '/'
}
rule factor {
<number>
}
token number {
\d+
}
}让我们检查一下。 首先,请注意我们与之前的变体相比如何更改了TOP规则。 使用%%运算符可以更轻松地表达片段重复。 比较两个正则表达式:
<number> [<op> <number> <ws>]*和
<number>* %% <op>第二个变化是引入了两个运算符集:+ 和 - 的 op1 以及 * 和 / 的 op2。 op1 中的运算符的优先级较低,它们出现在语法的顶级规则中。 换句话说,我们认为输入表达式的总和仅包含你要加或减的数字。
乘法和除法运算符具有更高的优先级,你应该将其结果总体上视为最高级别。 这就是为什么引入令牌而不是匹配数字的原因。 最后可以是数字,但首先是由*或/分隔的一系列因素。 在我们的案例中,一个因素基本上是一个数字。 我故意添加了一个单独的代理规则,factor,以保留名称的术语和因数,你经常可以在与编译器相关的文献中看到这些规则。
在动作类中,我们已经具有四个操作功能; 我们所需要做的只是为因子添加一个简单的方法并为术语创建操作。
class CalculatorActions {
. . .
method TOP($/) {
$/.make(process($<term>, $<op1>));
}
method term($/) {
$/.make(process($<factor>, $<op2>));
}
sub process(@data, @ops) {
my @nums = @data.map: *.made;
my $result = @nums.shift;
operation(~@ops.shift, $result, @nums.shift)
while @nums;
return $result;
}
method factor($/) {
$/.make($<number>.made);
}
method number($/) {
$/.make(+$/);
}
}如你所见,TOP 和 term 都实现相同的算法; 他们只是处理语法的不同部分(和不同的运算符)。
3.6. 测试代码
到目前为止,我们已经有了一个可以对表达式中任意数量的数字执行四个算术运算的计算器。 你可以提出测试用例,但你可能不想在脑海中计算出正确的结果,并对照每个测试用例进行检查。
Raku 发行版包括 Test 模块,该模块显着有助于简化测试用例循环。 该模块会导出一些功能,我们将使用其中一个名为 is 的功能。 由于计算器表达式的语法与 Raku 的语法一致,因此让我们要求它检查结果:
use Test;
. . .
for @cases -> $test {
my $result = Calculator.parse(
$test, :actions(CalculatorActions)).made;
my $correct = EVAL($result);
is($result, $correct, "$test = $correct");
}尝试不同的测试用例,包括那些混合使用运算符的测试用例。 例如:
ok 10 - 3 * 4 = 12
ok 11 - 100 / 25 = 4
ok 12 - 1 + 2 * 3 = 7
ok 13 - 1 + 2 - 3 * 4 / 5 = 0.6实际上,每个测试都必须检查两件事:1)是否对示例进行了解析,以及2)评估是否正确。 我们可以拆分测试以满足这一观察要求:
for @cases -> $test {
my $parse = Calculator.parse($test, :actions(CalculatorActions));
next unless isa-ok($parse, Match, "parsed $test");
my $result = $parse.made;
my $correct = EVAL($result);
is($result, $correct, "computed $test = $correct");
}输出将相应地更新:
ok 1 - parsed 3 + 4
ok 2 - computed 3 + 4 = 7
ok 3 - parsed 3 - 4
ok 4 - computed 3 - 4 = -1
. . .3.7. 添加更多能量
在本节中,我们将使计算器更加通用,因为我们将要添加幂运算符 **。 与以前的运算符集不同的是,幂运算符具有更高的优先级,必须在进行任何乘法或加法之前首先进行处理。
可以类似于我们之前对 * 和 / 进行的操作添加操作符。 让我们替换因子规则并为运算符本身定义令牌:
rule factor {
<number>* %% <op3>
}
token op3 {
'**'
}另一个需要做的细微变化是在数字令牌中添加空格。 你可以明确地做到这一点:
token number {
<ws> \d+ <ws>
}或通过将令牌转换为规则来隐式地:
rule number {
\d+
}更新操作类以支持新的运算符:
multi sub operation('**', $a is rw, $b) {
$a **= $b
}
method factor($/) {
$/.make(process($<number>, $<op3>));
}所有的辛苦工作都完成了(很简单,不是吗?)。 计算器现在处理五个运算符:
ok 26 - parsed 2 ** 3
ok 27 - computed 2 ** 3 = 8
ok 28 - parsed 2 + 3 ** 4
ok 29 - computed 2 + 3 ** 4 = 83
ok 30 - parsed 1 + 2 * 3 ** 4 - 5 * 6
ok 31 - computed 1 + 2 * 3 ** 4 - 5 * 6 = 133
ok 32 - parsed 2 ** 3 ** 4
ok 33 - computed 2 ** 3 ** 4 = 40963.8. 允许括号
计算器设计的最后一点是使其理解括号。 尽管看似艰巨的任务,但实际上实现起来非常简单。 这是因为括号内的任何内容都是遵循相同语法规则的另一种表达方式。 换句话说,如果看到括号,则可以从 TOP 递归开始。
计算括号内的值后,你将获得一个值,因此可以将其视为任何其他数字。 要扩展解析器,只需从数字中创建一个新值规则,然后在其中列出两个备选方案:
rule factor {
<value>* %% <op3>
}
rule value {
| <number>
| '(' <TOP> ')'
}value 方法获取上一级的值:
method value($/) {
$/.make($<number> ?? $<number>.made !! $<TOP>.made);
}而已。 仅需进行三个简单的更改,我们就可以解析更多复杂的表达式:
ok 34 - parsed 10 * (20 - 30)
ok 35 - computed 10 * (20 - 30) = -100
ok 36 - parsed 10 * 20 - 30
ok 37 - computed 10 * 20 - 30 = 170
ok 38 - parsed (5 * 6)
ok 39 - computed (5 * 6) = 30
ok 40 - parsed (10)
ok 41 - computed (10) = 10
ok 42 - parsed 1 - (5 * (3 + 4)) / 2
ok 43 - computed 1 - (5 * (3 + 4)) / 2 = -16.5我们的计算器已经准备好了。 在下一章中,我们将其集成到解释器中,以便它可以解析涉及变量的算术表达式。
4. 第四章 更好的解释器
本章的目的是利用前三章的所有成果来构建更好的解释器。 新的解释器将能够处理不同类型的数字,并对变量执行不同的算术运算。 为了使它变得更好,我们将从一个非常有用的附加功能开始-注释。
4.1. 跳过注释
注释对于任何编程语言都是必不可少的,因此让我们扩展 Lingua 语法以允许在我们的程序中对人类进行注释。
首先,我们将实现一个单行注释,该注释以井号(#)字符开头,并继续到该行的末尾,如下面的示例所示:
# Declare a variable
my alpha;
alpha = 100; # Assign a value我们的语法规定程序是一组用分号分隔的语句。
rule TOP {
<statement>* %% ';'
}语句是以下之一:变量声明,赋值或函数调用。
rule statement {
| <variable-declaration>
| <assignment>
| <function-call>
}我们如何在此处添加 comment 规则? 注释本身可以由匹配井字符后跟任意数量的非换行符的规则表示:
rule comment {
'#' \N*
}起初,你可能认为可以通过简单的方式将注释添加到 grammar 中:
rule statement {
| <comment>
| <variable-declaration>
| <assignment>
| <function-call>
}不幸的是,这行不通。 规则要求注释一直到行尾,而另一条规则则要求在其后加一个分号。 可能的解决方案是承认该程序不仅仅是语句列表。
rule TOP {
[
| <comment>
| <statement> ';'
]*
}现在,该程序包含注释和语句。 后者以分号结尾。
进行此更改后,在程序末尾的最后一条语句之后必须使用分号。 这是一个棘手的时刻,让我们花一些时间正确地理解它。
编写一个包含以下三个语句的简单程序:
my a;
a = 10;
say a程序的末尾没有分号,但是如果你运行它,你仍然会在输出中看到 10,就像最后一条指令也已执行一样。
实际上,grammar 无法完全解析输入文本。 你可以通过查看 Calculator.parse 方法的返回值轻松证明这一点,该方法对于该程序为 Nil。 因此,该语法不能确认程序的有效性,但是在解析程序时它仍然执行动作。 通过切换到实际的 AST 代,我们可以避免这种情况,我们将在以下各章中进行介绍。 同时,让我们更新解释器,以便它报告解析状态:
my $result = Lingua.parse($code, :actions(LinguaActions));
say $result ?? 'OK' !! 'Error';我们愿意允许的第二种注释类型是一对字符序列 / 和 / 之间的注释。 它们既可以包含单行注释,也可以包含多行注释,并且可以出现在代码的任何允许空白的地方。 例如:
my /* inline comment */ a;
# one-line comment
a = 10;
/* multi-line
comment */
say a;由于你无法控制用户在何处写注释,因此该任务似乎很困难。 如前所述,在允许空白的任何地方都允许注释。 Raku 已经为我们处理了空格,因此我们也可以要求它跳过注释吗?
Grammar 中的任何规则都隐含包含用于匹配空格的正则表达式。 例如,采用 assignment 规则:
rule assignment {
<variable-name> '=' <value>
}该规则可以用带有几个嵌入式 ws 正则表达式的 token 替换:
token assignment {
<variable-name> <ws> '=' <ws> <value>
}如果没有 <ws>,token 将要求你不要在等号周围使用空格。
a=10;
b=20;添加可选的空格使我们可以创建更多对人友好的程序:
a = 10;
b = 20;可以重新定义 ws 正则表达式。 默认情况下,它匹配单词外的任意数量的空格(包括无):
regex ws {
<!ww> \s*
}这是定义 /* */ 注释的理想位置。 正则表达式必须允许空格和注释定界符之间的任何文本序列:
regex ws {
<!ww> [
| \s*
| \s* '/*' \s* .*? \s* '*/' \s*
]
}由于存在许多斜线和星号,因此看起来很丑陋,但是可以按预期完成工作。 注意,必须在 / 和 / 字面值之前和之后都留一些空格。 另请注意,此语法方法是 regex,而不是 rule 或 token。
4.2. 复杂数字
解释器使用数字,我们已经可以很好地解析它。 让我们加入这两种语法,并让程序使用科学计数法处理所有数字,包括正数,负数,整数,浮点数和数字。
从第2章中获取数字语法的正文,并将其复制到 Lingua 的语法中。 Number 的 TOP 规则应成为 Lingua 中的 value 规则。
token value {
<sign>? [
| <integer>
| <floating-point>
] <exponent>?
}同样不要忘记更新动作类:
method value($/) {
$/.make(+$/);
}立即尝试以下程序:
my alpha;
my beta;
my gamma;
alpha = 3.14;
beta = 42;
gamma = -4.5E-2;
say alpha;
say beta;
say gamma;它应该解析数字并全部打印出来。 现在,此步骤已完全完成。
4.3. 复杂表达式
我们可以轻松地采取的下一步是将计算器语法合并到语言定义中。 让我们将现有的 value 方法重命名为 number,然后语言语法将使用在 Calculator 中定义的值。
grammar Lingua {
. . .
rule value {
| <number>
| '(' <expression> ')'
}
rule expression {
<term>* %% <op1>
}
token number {
<sign>? [
| <integer>
| <floating-point>
] <exponent>?
}
. . .
}此处的表达规则是计算器语法的前 TOP 规则。 对称更新操作类:
class LinguaActions {
. . .
method value($/) {
$/.make($<number> ??
$<number>.made !! $<exression>.made);
}
method expression($/) {
$/.make(process($<term>, $<op1>));
}
method number($/) {
$/.make(+$/);
}
}此后,可以通过任意复杂度的表达式来表示程序中的任何数字。 当前语法中唯一使用数字的地方是赋值。 我们可以用表达式替换它的右侧。
在语法上:
rule assignment {
<variable-name> '=' <expression>
}在 action 类中:
method assignment($/) {
%var{~$<variable-name>} = $<expression>.made;
}
method value($/) {
$/.make($<number> ??
$<number>.made !! $<expression>.made);
}更改测试程序以在其中包含一些表达式。 这是我的示例:
my pi;
pi = 22/7 - 0.001265; # very rough approximation
say pi;
my x;
x = 2 * (3 + 4);
say x; # prints 14别忘了我们也可以在代码中使用注释!
4.4. 使用变量
到目前为止,我们的表达式只能使用数字。 如果我们也可以在那里使用变量,那将更加方便。 为此,需要对语法进行少量更改。 就语法规则而言,在表达式中包含变量意味着允许在其中包含变量名称:
rule value {
| <number>
| <variable-name>
| '(' <expression> ')'
}没有与变量名标记关联的 made 属性,因此我们必须做一些简单的工作来访问存储:
method value($/) {
if $<number> {
$/.make($<number>.made);
}
elsif $<variable-name> {
$/.make(%var{$<variable-name>});
}
else {
$/.make($<expression>.made);
}
}值方法由三个分支组成,其任务是找到适当的数据以进一步传递。 对于变量,将进行哈希查找。
有了这些,解释器现在可以处理以下程序并计算地球赤道的长度(假设我们之前已经将值分配给pi):
my r;
r = 6371; # km
my d;
d = 2 * pi * r;
say d;4.5. 初始化声明
希望你注意到与第一章中的内容相比,进行最新更改非常容易。 本节将带来另一个此类示例。
让我们简化变量的创建,并允许使用可选的赋值进行声明。 所以代替
my x;
x = 10;我们可以在一行中表示两个步骤:
my x = 10;变量声明由变量声明规则处理,因此让我们使用可选的赋值子句对其进行更新:
rule variable-declaration {
'my' <variable-name> [ '=' <expression> ]?
}在操作中,检查是否存在表达式,并使用其值:
method variable-declaration($/) {
%var{$<variable-name>} =
$<expression> ?? $<expression>.made !! 0;
}使用以下附加功能重写测试程序:
my pi = 3.1415926;
my r = 6371; # km
my d = 2 * pi * r;
say d;该程序将打印结果,而我们只有不到 200 行代码(包括空行和其中带有单个花括号的行)。 Raku 语法真的很棒!
5. Grammar 学习
在本章中,我们将回顾到目前为止已创建的语法,并将尝试进行一些更改以使语法和操作更紧凑,更易读且更加用户友好。 语言越大,保持其代码可维护性就越重要。
5.1. 可执行的
本章要做的第一件事是使当前的解释器(成为编译器)成为适当的可执行程序,以便我们可以从命令行轻松调用它,并将包含Lingua程序的文件名传递给它:
./lingua my-prog.lnglingua 可执行文件必须检查你是否传递了文件名以及文件是否存在。 然后,它解析并执行输入程序。 这是完整的代码:
use lib '.';
use Lingua;
use LinguaActions;
error('Usage: ./lingua <filename>') unless @*ARGS.elems;
my $filename = @*ARGS[0];
error("Error: File $filename not found") unless $filename.IO.f;
my $code = $filename.IO.slurp();
my $result = Lingua.parse($code, :actions(LinguaActions));
say $result ?? 'OK' !! error('Error: parse failed');
sub error($message) {
note $message;
exit;
}错误函数将显示错误消息并终止程序。 它使用 note 内置函数,其行为类似于 say,但是将输出发送到标准错误流。 这里不使用 die 例程,因为它会打印有关错误位置的其他信息,在这种情况下并不需要。 抑制裸片的额外输出所需的行数与引入新功能所需的行数大致相同。
5.2. 组合和继承 Grammar
在 Lingua 语言中,我们允许以#字符开头的单行注释,以及 / 和 / 之间的内联和多行注释。 这样的注释也用在其他编程语言中,从语言语法中提取注释规则并将其放在单独的类中可能很有用。 这也使主要语言语法更小,更透明。
让我们回顾一下处理注释的现有 Lingua 语法的片段:
grammar Lingua {
rule TOP {
[
| <comment>
| <statement> ';'
]*
}
rule comment {
'#' \N*
}
regex ws {
<!ww> [
| \s*
| \s* '/*' \s* .*? \s* '*/' \s*
]
}
. . .
}其中大多数可以放到单独的 grammar 类中。 明智地将两种类型的注释区分开来也是明智的。
grammar CommentableLanguage {
regex ws {
<!ww> [
| \s*
| \s* <inline-comment> \s*
]
}
regex inline-comment {
'/*' \s* .*? \s* '*/'
}
rule one-line-comment {
'#' \N*
}
}CommentableLanguage 语法仅知道如何处理注释,但是由于它现在位于单独的类中,因此它可以作为另一种语言定义的基础。 在我们的例子中,Lingua 可以从中得出:
use CommentableLanguage;
grammar Lingua is CommentableLanguage {
. . .
}如果你将 CommentableLanguage 类放在单独的文件中,则 use 语句是必需的。
在 Lingua 中,现在唯一需要做的更改是在主代码中为单行注释使用专有名称:
rule TOP {
[
| <one-line-comment>
| <statement> ';'
]*
}其余所有操作都是自动完成的。 例如,现在 Raku 的 Grammar 类的默认 ws 正则表达式已替换为 CommentableLanguage 中的 ws。
我们可以通过提取负责解析数字的部分来进一步简化主要语法。 与注释一样,该部分也可以放在单独的类中。 但是,在这种情况下,最好使其成为角色并将其保存在单独的文件中。
role Number {
token number {
<sign>? [
| <integer>
| <floating-point>
] <exponent>?
}
token sign {
<[+-]>
}
token exp {
<[eE]>
}
token integer {
\d+
}
token floating-point {
<integer>? ['.' <integer>]
}
token exponent {
<exp> <sign>? <integer>
}
}以后,如果需要,你可以轻松修改 Number 角色以允许程序中使用其他类型的数字。 要将其附加到 Lingua 语法,请使用 does 关键字:
use CommentableLanguage;
use Number;
grammar Lingua is CommentableLanguage does Number {
. . .
}5.3. 复习计算器
来自计算器的语法部分包括彼此相似的一些部分。
rule expression {
<term>* %% <op1>
}
rule term {
<factor>* %% <op2>
}
rule factor {
<value>* %% <op3>
}但是首先,让我们考虑一下其中的量词。 星号允许任意多次重复的项,因数或值。 如果程序不包含任何内容,例如,如下所示,该怎么办:
my x;
x = ;
say x;这显然是错误的,但是 Lingua 语法不会返回 Nil。 它较早失败,从 Raku 产生了不希望的混乱输出:
Cannot shift from an empty Array
in sub process at /Users/ash/lingua/LinguaActions.rakumod (LinguaActions) line 52
in method factor at /Users/ash/lingua/LinguaActions.rakumod (LinguaActions) line 46
in regex factor at /Users/ash/lingua/Lingua.rakumod (Lingua) line 48
in regex term at /Users/ash/lingua/Lingua.rakumod (Lingua) line 44
in regex expression at /Users/ash/lingua/Lingua.rakumod (Lingua) line 40
in regex assignment at /Users/ash/lingua/Lingua.rakumod (Lingua) line 23
in regex statement at /Users/ash/lingua/Lingua.rakumod (Lingua) line 13
in regex TOP at /Users/ash/lingua/Lingua.rakumod (Lingua) line 6
in block <unit> at ./lingua line 13
Actually thrown at:
in method function-call at /Users/ash/lingua/LinguaActions.rakumod (LinguaActions) line 13
in regex function-call at /Users/ash/lingua/Lingua.rakumod (Lingua) line 27
in regex statement at /Users/ash/lingua/Lingua.rakumod (Lingua) line 13
in regex TOP at /Users/ash/lingua/Lingua.rakumod (Lingua) line 6
in block <unit> at ./lingua line 13这不是用户想要看到的。 编译器坏了,没有生成错误消息。 我们必须更改语法,并在期望表达的地方至少要求一个值。 最简单的修改是将 * 替换为 +:
rule expression {
<term>+ %% <op1>
}
rule term {
<factor>+ %% <op2>
}
rule factor {
<value>+ %% <op3>
}现在,我们自己控制错误消息:
Error: parse failed5.4. 使用 MULTI-RULES
表达式,项和因数这三个规则都具有相同的模式:一个规则重复两次,中间使用一个运算符。 我们可以使用Raku提供的用于类(因此用于语法)的多种方法来统一它们。 代替三个不同的标记 op1,op2 和 op3,让我们通过指定一个整数参数及其值来创建一个名称和三个选择。
multi token op(1) {
'+' | '-'
}
multi token op(2) {
'*' | '/'
}
multi token op(3) {
'**'
}值1到3对于语法本身并不重要; 对我们来说,它表示运营商的优先级:数字越大,优先级越高。
我们还必须使用这些运算符来更新上述规则:
rule expression {
<term>+ %% <op(1)>
}
rule term {
<factor>+ %% <op(2)>
}
rule factor {
<value>+ %% <op(3)>
}在操作中,我们将看不到参数值以及带有简单 op 的所有名称:
method expression($/) {
$/.make(process($<term>, $<op>));
}
method term($/) {
$/.make(process($<factor>, $<op>));
}
method factor($/) {
$/.make(process($<value>, $<op>));
}在这里可以清楚地看到动作方法是相同的,因此我们可以进一步减少代码,但首先,让我们尝试运行测试程序以确认转换的第一部分可以工作。
让我们继续并将这三个规则和这三种方法折叠为一条规则及其相应的通用方法。 再次,使用多方法。
rule expression {
<expr(1)>
}
multi rule expr(1) {
<expr(2)>+ %% <op(1)>
}
multi rule expr(2) {
<expr(3)>+ %% <op(2)>
}
multi rule expr(3) {
<expr(4)>+ %% <op(3)>
}
multi rule expr(4) {
| <number>
| <variable-name>
| '(' <expression> ')'
}这次,变化更大了。 我们引入了新的多规则 expr,它取代了 term 和 factor。 为了使 expr 方法统一,将 value 方法替换为 expr(4)。 这样做是为了能够从成为 expr(3) 的前一个因素访问作为 expr(4) 的前一个值。
之后,可以将带有参数 1、2 和 3 的前三个 expr 备选方案替换为具有 $n + 1 的简单数学运算的单个通用规则,从而使我们进入下一个层次。
multi rule expr($n) {
<expr($n + 1)>+ %% <op($n)>
}现在,语法包括两个选择:expr($n) 和 expr(4)。 当解析器达到第三级时,它接下来将选择一个更具体的 expr(4) 替代方案,从而停止递归。
在动作类中,保留以下两种方法; 它们替换了方法的表达式,项,因子和值:
method expression($/) {
$/.make($<expr>.made);
}
method expr($/) {
if $<number> {
$/.make($<number>.made);
}
elsif $<variable-name> {
$/.make(%var{$<variable-name>});
}
elsif $<expr> {
$/.make(process($<expr>, $<op>));
}
else {
$/.make($<expression>.made);
}
}起初,似乎我们使语法和动作的透明度降低了,但是如果你需要引入更多的运算符,则只需在语法中添加新的 op(n) 规则,并将其添加到动作类中 。
5.5. 摆脱全局变量
为了存储变量值,我们使用了全局哈希 %var。 让我们使程序更加美观,然后将存储空间作为数据成员移至 action 类。
class LinguaActions {
has %!var;
. . .
}当然,你应该立即将所有出现的 %var 替换为 %!var,例如,在赋值操作中(LinguaActions 类中还有三个此类位置):
method assignment($/) {
%!var{~$<variable-name>} = $<expression>.made;
}最后,由于我们需要在内存中放置哈希值,因此你需要在调用 parse 方法之前实例化 action 类:
my $result = Lingua.parse($code,
:actions(LinguaActions.new));5.6. 更好的变量名
在本章结束之前,让我们再进行一些小的但非常有效的补充。 之前,我们制作了一个临时令牌来解析变量名:
token variable-name {
\w+
}该令牌与所谓的单词字符匹配,其中包括字母,数字和下划线字符。 这种简单解决方案的缺点是,它允许使用数字作为变量名称的第一个字符,并且以下代码在形式上在语法上是正确的:
my 4 = 3;
say 4;为了解决这种情况,让我们使用与字母匹配的预定义令牌:
token variable-name {
[<:alpha> | '_'] \w*
}现在,变量名只能以字母或下划线字符开头,然后是由任何单词字符组成的可选部分。 例如,以前的错误程序可以这样转换:
my var_4 = 3;
say var_4;5.7. 函数接收表达式
仍然保留在语法中的另一个即席解决方案是函数调用。 它只能以变量名作为参数。 我们将为功能专门介绍一章,但现在,让我们允许以下调用:
say 42;
say 100 + 300 / 3 ** (7 - 5);将表达式而不是变量传递给函数。 因此,更新函数调用规则:
rule function-call {
<function-name> <expression>
}该操作还需要更新。 很棒的事情是,通过切换到表达式,我们使操作更加简单。 这是以前的样子:
method function-call($/) {
say %!var{$<variable-name>} if $<function-name> eq 'say';
}这是现在的样子:
method function-call($/) {
say $<expression>.made;
}函数仅使用在其他位置计算出的值,而不进行任何变量检查。
在本章中,对语法及其相关代码进行了许多转换。 这使语法变得更加透明,甚至允许我们添加一些不错的扩展。 请查阅仓库以确保我们位于同一页面上。
6. 处理字符串
到目前为止,该语言仅适用于数字(整数和浮点数),包括常规计数法和科学计数法。 在接下来的两章中,我们将更新语言并将其集成到其他数据类型中:字符串,数组和哈希。 让我们首先从字符串开始。
6.1. 字符串
第一个目标是在变量赋值(或初始化)和函数调用中允许使用双引号引起来的字符串:
my str = "Hello, World";
say str;
say "Hello indeed";在这两种情况下,grammar 都期望一个表达式:
rule variable-declaration {
'my' <variable-name> [ '=' <expression> ]?
}
rule function-call {
<function-name> <expression>
}因此,最简单的解决方案是在可能出现数字的同一级别上将字符串添加为表达式的变体:
multi rule expr(4) {
| <number>
| <string>
| <variable-name>
| '(' <expression> ')'
}给 action 也添加一个分支:
method expr($/) {
if $<number> {
$/.make($<number>.made);
}
elsif $<string> {
$/.make($<string>.made);
}
. . .
}字符串本身被定义为双引号之间的字符序列:
rule string {
'"' .*? '"'
}它的 AST 属性只是一个字符串化的匹配对象:
method string($/) {
$/.make(~$/)
}那是一个低落的果实,但是这种方法有两个问题。 首先,引号成为字符串的一部分。 其次,如果用户将字符串放入算术表达式中(例如 "Hello" + "World"),则编译器将失败并出现异常。
第一个问题很容易解决:在 action 中创建一个捕获组并以 [0] 的索引对其进行访问:
rule string {
'"' ( <-["]>* ) '"'
}
. . .
method string($/) {
$/.make(~$/[0]);
}顺便说一下,请注意,我们也开始更改字符串的正则表达式。 它可以包含任何期望双引号的字符。 我们将很快需要更多此类。
第二个问题也是可以解决的,但是 grammar 有了更重要的重建。 让我们返回 value 规则,但是这次,它可以是算术表达式或字符串:
grammar Lingua is CommentableLanguage does Number {
. . .
rule variable-declaration {
'my' <variable-name> [ '=' <value> ]?
}
rule assignment {
<variable-name> '=' <value>
}
rule function-call {
<function-name> <value>
}
rule value {
| <expression>
| <string>
}
. . .
}因此,在赋值和函数调用中需要一个字符串 String(作为一种 value 值)。
在 action 中,进行了类似的更改。 我们使用值而不是表达式:
class LinguaActions {
has %!var;
method variable-declaration($/) {
%!var{$<variable-name>} =
$<value> ?? $<value>.made !! 0;
}
method assignment($/) {
%!var{~$<variable-name>} = $<value>.made;
}
method function-call($/) {
say $<value>.made;
}
. . .
method value($/) {
if $<expression> {
$/.make($<expression>.made);
}
elsif $<string> {
$/.make($<string>.made);
}
}
. . .
}结果正是所需要的。 普通字符串会被解析和理解,而尝试将它们与数字或表达式一起使用会导致解析错误。
6.2. 转义引号
很明显,上面定义的字符串本身不能包含双引号。 让我们将 " 作为唯一可能的引号,但允许在字符串中转义引号字符:
say "Hello, \"World\"!";当前,解析器在第二个引号处停止并以错误终止:
Hello, \
Error: parse failed要允许转义的引号,string 规则必须使用所有非引号和非反斜杠字符,如果看到反斜杠,则仅将 \" 序列视为有效:
token string {
'"' ( [
| <-["\\]>+
| '\\"'
]* )
'"'
}从现在起,我们希望使用 token 而不是 rule,以避免在开引号后跳过空格。
在 Raku 中,你可以自由地对正则表达式进行格式化,以形成某种 ASCII 图形,从而有助于更快地掌握正则表达式。 正如我们之前所做的,再次添加了一个附加的竖线以可视化备选分支。
现在允许使用转义的引号字符,但是在所有其他情况下,反斜杠本身都变为非法字符。 让我们添加另一个转义序列 \\,以在字符串中表达单个反斜杠:
token string {
'"' ( [
| <-["\\]>+
| '\\"'
| '\\\\'
]* )
'"'
}不允许所有其他序列,例如 "\W" 是一个错误。 以下是带有反斜杠和引号的有效字符串的一些示例。 字符串可以包含换行符,也可以为空:
say "\\";
say "\"";
say "\\\\";
say "\"\"";
say "multi-
line";
say "";由于我们不需要在输出中使用转义的反斜杠,因此应在将其进一步传递之前将其从字符串中删除:
method string($a) {
my $s = ~$a[0];
$s ~~ s:g/\\\"/"/;
$s ~~ s:g/\\\\/\\/;
$a.make($s);
}(注意,否则在发生运行时错误时,我们必须更改方法参数的名称:Cannot assign to a readonly variable ($/) or a value.)
6.3. 变量插值
与 Raku 本身一样,如果 Lingua 中的变量出现在字符串中,我们希望对其进行插值。 让我们使用以下语法:插入变量,在变量名前加一个美元符号,如下例所示:
my name = "John";
say "Hello, $name!";如果是这样,则必须根据需要转义字面值:
say "5\$";在字符串 token 中引入新的转义序列以及以 $ 开头的新备选分支:
token string {
. . .
| '\\$'
| '$' <variable-name>
. . .
}变量名本身由另一个标记 variable-name 解析。
当解析器在字符串中看到插值候选时,它将在 match 对象中创建一个数组,其中包含所有变量名的列表(即使只有一个)。 这些名称可以从 $a[0]<variable-name> 中读取。 下一步是将所有此类事件替换为变量的内容。
method string($a) {
my $s = ~$a[0];
for $a[0]<variable-name>.reverse -> $var {
$s.substr-rw($var.from - $a.from - 2,
$var.pos - $var.from + 1) = %!var{$var};
}
. . .
}循环需要一些注释。 $a 容器托管一个 Match 对象(Match 是 Raku 中的一个内置类,用于保留正则表达式匹配的结果),该对象保留对整个输入字符串的引用:不仅是 $s 中保存的部分,而且是整个程序的解析过程 。 它的 from 和 pos 属性显示d当前字符串的边缘(在我们的示例中,Hello, $name!)。
$var 是另一个 Match 对象,它在源文本中保留变量名的位置。 使用 substr-rw 方法的就地替换会将变量名称以及前面的美元字符替换为变量的值。
为了简化插值变量名称的开始和结束位置的计算,从字符串的末尾到字符串的开始执行替换(请注意循环中的 reverse 方法)。
因此,一个字符串中可能有多个插值变量:
my name = "John";
my another_name = "Carla";
say "Hello, $name and $another_name!";6.4. 索引字符串
获得给定字符将是对我们语言中字符串的一个很好的补充。 让我们允许这样的标准语法:
my s = "abcdef";
say s[3]; # prints d我们仅允许在字符串存储在变量中的情况下建立索引,因此让我们更新相应的规则以在方括号中具有可选的整数索引:
multi rule expr(4) {
| <number>
| <variable-name> [ '[' <integer> ']' ]?
| '(' <expression> ')'
}在 action 中,检查 <integer> 属性是否存在,并返回请求的字符:
method expr($/) {
. . .
elsif $<string> {
$/.make($<string>.made);
}
elsif $<variable-name> {
if $<integer> {
$/.make(
%!var{$<variable-name>}.substr(
+$<integer>, 1));
}
else {
$/.make(%!var{$<variable-name>});
}
}
. . .
}索引不适用于字符串插值,但是你始终可以使用一个临时变量来实现目标:
my ch = s[4];
say "The 4th character is \"$ch\""; # e作为练习,请尝试在插值字符串中实现字符串索引。 准备考虑在索引之外转义方括号。
7. 数组和散列
在本章中,我们将用聚合数据类型:数组和散列来扩展 Lingua 语言。从这里开始,我们将调用数字和字符串标量变量。
7.1. 数组
数组是元素的集合,它们共享相同的变量名,并通过整数索引访问。下面介绍一下数组声明的语法。
my data[];它与声明标量变量(可以保存数字或字符串)使用相同的 my 关键字,并且在名称后有两个方括号。variable-declaration grammar 规则现在可以分成两部分,一部分用于数组,一部分用于标量。
rule variable-declaration {
'my' [
| <array-declaration>
| <scalar-declaration>
]
}这里先用数组,因为数组的定义在变量名后面有额外的字符,可以提前抓取。
或者,我们可以引入一个新的关键字,比如说 arr,来定义数组,而不是 my,在这一点上简化解析:arr data。但是,让我们回到我的选择,my data[],因为当我们来到初始化的时候,它也有自己的优势,减少了保留的关键字数量。
之前的标量变量声明规则迁移到一个单独的规则中。
rule array-declaration {
<variable-name> '[' ']'
}
rule scalar-declaration {
<variable-name> [ '=' <value> ]?
}新的 array-declaration 规则需要一对方括号,还没有包含初始化器部分。
在 action 中,我们还需要区分数组和标量,我们可以通过检查 $<array-declaration> 匹配对象的存在来实现。
method variable-declaration($/) {
if $<scalar-declaration> {
%!var{$<scalar-declaration><variable-name>} =
$<scalar-declaration><value> ??
$<scalar-declaration><value>.made !! 0;
}
elsif $<array-declaration> {
%!var{$<array-declaration><variable-name>} = $[];
}
}它可以使用,但由于嵌套匹配对象键的原因,看起来太过超负荷了。事实上,没有必要这样做,因为可以为每一种情况创建单独的 action。
method scalar-declaration($/) {
%!var{$<variable-name>} = $<value> ?? $<value>.made !! 0;
}
method array-declaration($/) {
%!var{$<variable-name>} = $[];
}有了这个变化,就不再需要 variable-declaration 方法了,可以从 LinguaActions 类中删除。
你可以暂时用下面的代码来代替它,只是想看看解析器是如何处理数组的。
method variable-declaration($/) {
dd %!var;
}该方法在每一个变量声明后都会显示变量存储包含的内容。让我们用实际操作来测试一下。
my x = 3;
say x;
my data[];这个程序编译成功,可以看到 %!var 的哈希变化。
Hash %!var = {:x(3)}
3
Hash %!var = {:data($[]), :x(3)}
OK7.2. 给数组项赋值
OK,我们可以创建一个数组,是时候给它的元素填充一些数据了。
data[0] = 10;
data[1] = 20;assignment 规则的更新方式与上一章中我们对字符串索引的更新方式类似,可以在方括号中添加一个可选的整数索引。
rule assignment {
<variable-name> [ '[' <integer> ']' ]? '=' <value>
}在相应的 action 中,索引的存在表示我们正在处理一个数组,否则就是一个标量变量。
method assignment($/) {
if $<integer> {
%!var{~$<variable-name>}[+$<integer>] =
$<value>.made;
}
else {
%!var{~$<variable-name>} = $<value>.made;
}
}用上述赋值运行程序后,data 变量将在存储中保留两个值。
Hash %!var = {:data($[10, 20])}7.3. 题外话。语法的乐趣
在转向更多的数组和哈希特性之前,让我们先对 grammar 进行一下改造。在赋值方法中,if-else 检查占据了比"有用"代码更多的行数。我们可以做两个改造,让方法更紧凑。
首先,让我们重复一下将一条规则一分为二的技巧。我们可以用两个子规则来代替一个通用的赋值规则。
rule assignment {
| <array-item-assignment>
| <scalar-assignment>
}
rule array-item-assignment {
<variable-name> [ '[' <integer> ']' ] '=' <value>
}
rule scalar-assignment {
<variable-name> '=' <value>
}这让 grammar 变得更加啰嗦,但 action 变得更加紧凑。
method array-item-assignment($/) {
%!var{~$<variable-name>}[+$<integer>] = $<value>.made;
}
method scalar-assignment($/) {
%!var{~$<variable-name>} = $<value>.made;
}第二种可能的解决方案是,保留原有的 assignment 规则,根据匹配对象的内容,使用方法签名中的 where 子句来分派调用。
multi method assignment($/ where $<integer>) {
%!var{~$<variable-name>}[+$<integer>] = $<value>.made;
}
multi method assignment($/ where !$<integer>) {
%!var{~$<variable-name>} = $<value>.made;
}multi 方法的第二个变体的签名中的负条件 !$<integer> 是可选的,但为了代码的清晰性,我更愿意保留它。
还有两个 action 可以用同样的方式重写。value action。
multi method value($/ where $<expression>) {
$/.make($<expression>.made);
}
multi method value($/ where $<string>) {
$/.make($<string>.made);
}另一个带有大的 if-elsif-else 条件的 action 是 expr, 我们也转换一下:
multi method expr($/ where $<number>) {
$/.make($<number>.made);
}
multi method expr($/ where $<string>) {
$/.make($<string>.made);
}
multi method expr($/ where $<variable-name> && $<integer>) {
$/.make(%!var{$<variable-name>}.substr(+$<integer>, 1));
}
multi method expr($/ where $<variable-name> && !$<integer>) {
$/.make(%!var{$<variable-name>});
}
multi method expr($/ where $<expr>) {
$/.make(process($<expr>, $<op>));
}
multi method expr($/ where $<expression>) {
$/.make($<expression>.made);
}这些方法现在看起来很琐碎。请注意,有些候选者在匹配对象中检查多个键,例如:$<variable-name> && !$<integer>。
7.4. 访问数组元素
接下来的目标是开始使用单个数组项,从下一个片段中就可以看出:
say data[0];
say data[1];
my n = data[0] * data[1];
say n;我们目前的 action 类已经支持字符串索引,而这正是我们要扩展的地方。
multi method expr($/ where $<variable-name> && $<integer>) {
if %!var{$<variable-name>} ~~ Array {
$/.make(%!var{$<variable-name>}[+$<integer>]);
}
else {
$/.make(%!var{$<variable-name>}.substr(
+$<integer>, 1));
}
}该方法检查存储在 %!var 散列中的变量类型,如果是数组,则返回请求的元素。另一个分支和之前一样,对字符串进行操作。
通过将代表数组(和字符串)索引的序列提取到一个单独的规则中,可以再次简化 grammar。
rule index {
'[' <integer> ']'
}当你取值时,在 assignment 和 expr 内使用新的规则。
rule assignment {
<variable-name> <index>? '=' <value>
}
. . .
multi rule expr(4) {
| <number>
| <variable-name> <index>?
| '(' <expression> ')'
}如果你想改变索引的语法,比如说,把 data:3 改为 data[3],有一个地方可以做到,那就是 index 规则。
action 也必须适配。索引的属性是一个整数值。
method index($/) {
$/.make(+$<integer>);
}因此你应该用 $<index>.made 从其他方法中读取。
multi method assignment($/ where $<index>) {
%!var{~$<variable-name>}[$<index>.made] = $<value>.made;
}
multi method assignment($/ where !$<index>) {
%!var{~$<variable-name>} = $<value>.made;
}
. . .
multi method expr($/ where $<variable-name> && $<index>) {
if %!var{$<variable-name>} ~~ Array {
$/.make(%!var{$<variable-name>}[$<index>.made]);
}
else {
$/.make(%!var{$<variable-name>}.substr(
$<index>.made, 1));
}
}
multi method expr($/ where $<variable-name> && !$<index>) {
$/.make(%!var{$<variable-name>});
}再次,多余的条件,如在 where 子句中使用 !$<index> 是为了使代码更易读;如果没有这些条件,multi 方法也可以正确地调度。
7.5. 列表赋值
到目前为止,数组可以创建,但你必须逐一分配它们的元素。让我们允许列表赋值和初始化。
my data[] = 111, 222, 333;
data = 7, 9, 11;这里出现了一个新的语法元素—逗号。它与语言中的其他结构不冲突,因此可以很容易地嵌入到 grammar 中。
rule array-declaration {
<variable-name> '[' ']' [ '=' <value>+ %% ',' ]?
}
rule assignment {
<variable-name> <index>? '=' <value>+ %% ','
}在这两种情况下,都使用了 value 规则,这意味着你可以使用数字、字符串和算术表达式作为数组元素的初始化值。
my strings[] = "alpha", "beta", "gamma";
say strings[1]; # beta
my arr[] = 11, 3 * 4, 2 * (6 + 0.5);
say arr[0]; # 11
say arr[1]; # 12
say arr[2]; # 13为了在 action 中实现,让我们做一个辅助方法 init-array,取变量的名字和值的列表。
method init-array($variable-name, @values) {
%!var{$variable-name} = $[];
for @values -> $value {
%!var{$variable-name}.push($value.made);
}
}
multi method array-declaration($/ where $<value>) {
self.init-array($<variable-name>, $<value>);
}
multi method assignment($/ where !$<index>) {
if %!var{$<variable-name>} ~~ Array {
self.init-array($<variable-name>, $<value>);
}
. . .
}在创建新数组的时候,也可以用 Array.new 来代替 $[]。
例如, 与 operator 函数不同,init-array 例程是一个方法,因为它必须访问变量存储 %!var。
7.6. 打印数组
对于数组来说,另一个真正需要的是允许在一条指令中打印所有的元素。我们希望将整个数组的元素传递给 say 函数,而不是列出单独的项。
my data[] = 5, 7, 9;
say data;事实上,Raku 已经可以做到这一点,因为我们对 say 的实现只是将整个容器传递给 Raku 的 say,而 Raku 的 say 会打印出这样的数据。
[5 7 9]让我们不那么谦虚,像以前那样,通过检查变量的类型来创建自己的输出格式。
method function-call($/) {
my $object = $<value>.made;
if $object ~~ Array {
say $object.join(', ');
}
else {
say $object;
}
}这个函数将数组打印为以逗号形式分隔的列表项。
5, 7, 97.7. 散列
在本章的剩余部分,我们将在 Lingua 语言中实现哈希。在数组的例子中,你已经看到了大部分的想法,所以这些变化应该是透明的、明显的。
所以,我们要实现几个东西:声明、带初始化的声明、对整个散列和单个元素进行赋值、读取单个值和打印散列。
下面的片段演示了我们使用的语法。要声明一个散列,在变量名后使用一对花括号。
my data{};初始化和赋值使用逗号分隔的键-值对列表来完成。键始终是字符串,值可以是任何标量值(数字或字符串)。键和值之间的分隔符是冒号。
my hash{} = "alpha" : 1, "beta": 2, "gamma": 3;
my days{};
days = "Mon": "work", "Sat": "rest";Grammar 中包括一个单独的哈希声明规则。
rule variable-declaration {
'my' [
| <array-declaration>
| <hash-declaration>
| <scalar-declaration>
]
}
rule hash-declaration {
<variable-name> '{' '}' [
'=' [ <string> ':' <value> ]+ %% ','
]?
}assignment 规则应该知道如何处理哈希。这个时候,可以在不创建新的规则的情况下,就地修改。
rule assignment {
<variable-name> <index>? '='
[
| [ <string> ':' <value> ]+ %% ','
| <value>+ %% ','
]
}在 action 中,要仔细实现声明和散列赋值方法。它们都使用共同的方法 init-hash,来设置散列的键和值。
method init-hash($variable-name, @keys, @values) {
%!var{$variable-name} = Hash.new;
while @keys {
%!var{$variable-name}.{@keys.shift.made} =
@values.shift.made;
}
}
multi method hash-declaration($/) {
self.init-hash($<variable-name>, $<string>, $<value>);
}
multi method assignment($/ where !$<index>) {
. . .
elsif %!var{$<variable-name>} ~~ Hash {
self.init-hash($<variable-name>,
$<string>, $<value>);
}
. . .
}哈希实现的另一个部分是允许通过键访问值。重新使用 index 规则并使其成为两个备选的集合是明智的。
rule index {
| <array-index>
| <hash-index>
}
rule array-index {
'[' <integer> ']'
}
rule hash-index {
'{' <string> '}'
}在已存在的方法中使用新的规则。where 子句收到一个额外的条件,以确保我们得到了我们想要的规则。
multi method assignment($/ where $<index> &&
$<index><array-index>) {
%!var{$<variable-name>}[$<index>.made] =
$<value>[0].made;
}
multi method assignment($/ where $<index> &&
$<index><hash-index>) {
%!var{$<variable-name>}{$<index>.made} =
$<value>[0].made;
}
multi method assignment($/ where !$<index>) {
. . .
elsif %!var{$<variable-name>} ~~ Hash {
self.init-hash($<variable-name>,
$<string>, $<value>);
}
. . .
}新的 index 规则已经可以在 expr(4) 规则中工作了,它允许我们使用 hash{"key"} 语法通过给定的散列键读取值。我们需要做的就是更新 expr 方法,让它知道新的数据结构。
multi method expr($/ where $<variable-name> && $<index>) {
. . .
elsif %!var{$<variable-name>} ~~ Hash {
$/.make(%!var{$<variable-name>}{$<index>.made});
}
. . .
}在测试程序中添加下面这几行,并确认是否有效。
days{"Tue"} = "work";
say days{"Sat"};最后,教 say 函数打印哈希值。
method function-call($/) {
. . .
elsif $object ~~ Hash {
my @str;
for $object.keys.sort -> $key {
@str.push("$key: $object{$key}");
}
say @str.join(', ');
}
. . .
}如果你善于使用 map 方法,可以尝试制作一个更好的函数版本。say days; 的预期输出应该是这样的。
Mon: work, Sat: rest, Tue: work7.8. 复习和测试
让我们看看 Lingua 语言的现状。我们做了很多的工作,实现了对数字、字符串、数组和哈希的支持。我们可以改变变量的内容,并打印出变量的值。让我们再做一小步,允许变量作为数组索引或哈希键。
rule array-index {
'[' [ <integer> | <variable-name> ] ']'
}
rule hash-index {
'{' [ <string> | <variable-name> ] '}'
}相应的 action 可以转化成琐碎的 pair 对的 multi 方法。
multi method array-index($/ where !$<variable-name>) {
$/.make(+$<integer>);
}
multi method array-index($/ where $<variable-name>) {
$/.make(%!var{$<variable-name>});
}
multi method hash-index($/ where !$<variable-name>) {
$/.make($<string>.made);
}
multi method hash-index($/ where $<variable-name>) {
$/.make(%!var{$<variable-name>});
}请参考仓库,检查是否有正确的文件,如果有的话,就可以运行下面的测试程序,这个测试程序使用了此刻实现的大部分功能。
# Illustrating the Pythagorean theorem
my a = 3;
my b = 4;
my c = 5;
my left = a**2 + b**2;
my right = c**2;
say "The hypotenuse of a rectangle triangle with the
sides $a and $b is indeed $c, as $left = $right.";
/* Using floating-point numbers for
computing the length of a circle */
my pi = 3.1415926;
my R = 7;
my c = 2 * pi * R;
say "The length of a circle of radius $R is $c.";
# A list of prime numbers
my n = 5;
my data[] = 2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31;
my nth = data[n];
say "$n th prime number is $nth.";
# Demonstrating the use of hashes
my countries{} =
"France": "Paris", "Germany": "Berlin", "Italy": "Rome";
my country = "Italy";
my city = countries{country};
say "$city is the capital of $country.";该程序打印的结果如下:
$ ./lingua test22.lng
The hypotenuse of a rectangle triangle with the
sides 3 and 4 is indeed 5, as 25 = 25.
The length of a circle of radius 7 is 43.9822964.
5 th prime number is 13.
Rome is the capital of Italy.
OK解释器对程序的理解是相当迷人的,这在以前是不曾有过的。你写了它,你可以在里面做很多修改,程序仍然会显示出你所期望的结果。
在接下来的章节中,我们将从更复杂的方面来研究语言。
8. 创建抽象语法树
在这一章中,我们将致力于实现 AST,即抽象语法树,它以连接节点的形式来表示程序,这些节点负责原子动作,如变量声明,或计算两个值之和,或调用函数等。这可能是本书中最难也是最费脑的一章。
但首先,让我来证明一下为什么增加另一层抽象会有好处。
8.1. 想到了 if 这个关键字
在前几章中,我们实现了很多可以线性执行的功能。现在是时候考虑条件语句和用户定义的函数了。接下来的小例子证明,我们必须先做一个大的转变,然后才能继续进行。
让我们设想一下,我们要实现影响函数调用的 if 子句。所以,如果条件为 false,就可以禁用这个动作。
my condition = 0;
if condition say "Passed";更新 grammar,并加入一个可选的条件部分:
rule function-call {
['if' <variable-name>]? <function-name> <value>
}在 action 中,检查变量的值,并决定是否继续进行函数调用。
method function-call($/) {
if $<variable-name> {
my $condition = %!var{$<variable-name>};
return unless $condition;
}
. . .
}在条件变量的不同值下运行程序,你会发现它的表现与预期的一样:当变量为 0 时,Passed 字符串不会被打印出来。将变量设置为任何非零值,字符串就会被打印出来。
这似乎是一个可行的解决方案,即使你改变语法,让 if 关键字出现在后缀子句中,也是可行的:
rule function-call {
<function-name> <value> ['if' <variable-name>]?
}事实上 action 没有发生变化。现在的测试程序看起来是这样的:
my condition = 0;
say "Passed" if condition;让我们撤销上次的改动,试着把 if 关键字概括一下,并允许它在变量赋值中出现,就可以写成这样了:
my condition = 0;
if condition say "Passed";
my x = 8;
x = 9;
if condition x = 10;
say x;当然,也可以将条件嵌入到 assignment 规则中:
rule assignment {
['if' <variable-name>]?
<variable-name> <index>? '='
[
| [ <string> ':' <value> ]+ %% ','
| <value>+ %% ','
]
}这里有两个困难。
首先,匹配对象中现在有两个 variable-name 键,我们必须用 $<variable-name>[0] 和 $<variable-name>[1] 来引用它们。在上面的例子中,在其中一个赋值中,x = 9,变量名位于第 0 个元素中,而在第二个赋值中,if condition x = 10,它就会到第1个元素中。这个问题可以通过使用命名捕获,或者只看 $<variable-name> 数组的长度就可以很容易解决。
第二个问题是,我们有多个 assignment multi 方法的变体,因此我们必须更新所有的变体。这是一个巨大的重复代码,而对于其他可能的语句,我们必须这样做,因为我们要允许一个 if 子句。
让我们在 grammar 中尝试在更接近于 TOP 规则的层面上工作。
rule statement {
| <variable-declaration>
| [ 'if' <variable-name> ]? <assignment>
| [ 'if' <variable-name> ]? <function-call>
}重复的部分可以转换为规则:
rule statement {
| <variable-declaration>
| <condition>? <assignment>
| <condition>? <function-call>
}
rule condition {
'if' <variable-name>
}不同赋值的所有变体(例如,赋值给标量变量,或赋值给数组的元素,或在哈希中设置一个值)都在一个点上处理。
处理条件也可以在一个地方,在新 statement 动作中完成:
method condition($/) {
$/.make($<variable-name>.made ?? 1 !! 0);
}
method statement($/) {
if $<condition> {
my $condition = $<condition>.made;
fail unless $condition;
}
}看上去很好,但没有效果。程序忽略了这个条件,而不管它的值。
Passed
10
OK让我们调试这种行为,并将打印指令嵌入到方法中。
method statement($/) {
if $<condition> {
my $condition = $<condition>.made;
say "test condition = $condition";
fail unless $condition;
}
}
multi method assignment($/ where !$<index>) {
. . .
else {
say "assign $<variable-name> to " ~ $<value>[0].made;
%!var{$<variable-name>} = $<value>[0].made;
}
}在输出中,你会看到这些方法被调用的顺序:
assign x to 9
assign x to 10
test condition = 0
10
OK所有的赋值都发生在条件检查之前。在第四章的跳过注释一节中,我们已经遇到过类似的情况,在最后一条语句后面没有分号的程序的例子中,我们已经遇到过类似的情况。整个程序没有通过语法检查,但它的最后一条语句却被执行了。
下面是两行有问题的代码之一。
if condition x = 10;它是我们语言定义中的一个语句。为了满足 statement 规则,解析器必须检查它的备选语句,这里是指具有 assignment 规则的 statement:
rule statement {
. . .
| <condition>? <assignment>
. . .
}因此,condition 和 assignment 必须匹配,才能使整个 statement 规则成功。只要 assignment 规则匹配,它的动作方法就会被触发,赋值就会发生。
同理,可以跟踪 statement 规则的第三种替代方法的调用,可以看到,在解析器利用 condition 变量之前,打印发生了,而 function-call 规则的动作发生的时间比我们理解的不应该调用它的时间更早,这就使得行
if condition say "Passed";的行为是不正确的。
你可以尝试把所有的代码从动作中移到 statement 规则中,在语句规则中检查条件,或者设置一些保持 condition 检查值的全局变量,但所有这些方法都是容易出错的,会让编译器的代码变得面条化。还有一个更好的替代方法,就是 AST。
在接下来的章节中,我们将研究一组类来实现 Lingua 的 AST 需求。所有的 AST::* 定义都将保存在一个单独的文件 LinguaAST.rakumod 中,因此你必须在 LinguaActions.rakumod 文件中添加使用 LinguaAST; 指令。
8.2. AST 块
为了使整个过程简单化,我们从最小的程序开始。该程序包含一条声明变量的语句。
my a;这个程序可以通过一个 AST 节点来呈现。让我们称它为 AST::ScalarDeclaration,并给它两个描述变量的属性:它的名字和值。在给定的程序中,初始值不是由用户设置的,所以我们将以 0 来初始化它。

目标已经确定了,那么让我们用代码来实现。从图中你可能猜到了,我们要创建一个 Raku 类。从一开始就继承一个普通的基类可能会有帮助,此刻可以空出一个基类。
class ASTNode {
}
class AST::ScalarDeclaration is ASTNode {
has Str $.variable-name;
has $.value;
}AST:::ScalarDeclaration 节点代表了整个程序,但应该存在一些共同的起始节点,对于每一个可能的程序都是一样的。让我们再创建一个类来表示 TOP 规则。正如你在前几章中所记得的那样,我们的 TOP 规则可以匹配语句或多行注释。
rule TOP {
[
| <one-line-comment>
| <statement> ';'
]*
}没有必要为注释创建 AST 节点。注释很好地被解析器识别,但它们不会发出任何可执行的代码。所以我们只在程序的 AST 中省略它们。顶层 AST 节点的属性是一个可能的语句数组,也是 `ASTNode`s。
class AST::TOP is ASTNode {
has ASTNode @.statements;
}这对我们的程序来说已经足够了。这就是产生的 AST 的样子。

稍后,我们可以沿着树枝行走,执行指令。但首先,让我们改变语法动作,使其产生 AST 节点。
标量声明动作既可以执行赋值,也可以不执行。在我们的程序中,我们只有一个声明,所以让我们只修改两个多方法中的一个。
multi method scalar-declaration($/ where !$<value>) {
$/.make(AST::ScalarDeclaration.new(
variable-name => ~$<variable-name>,
value => 0,
));
}这里,我们要创建 AST::ScalarDeclaration 节点。variable-name 属性取变量的名称,值属性设为 0。
为此,我们不仅要改变现有的动作,还需要定义 scalar-declaration 上面的方法,如 TOP、statement 和 variable-declaration 等。
variable-declaration 方法现在只是一个代理方法,将 made 的值传递给下一级的方法。
method variable-declaration($/ where $<scalar-declaration>) {
$/.make($<scalar-declaration>.made);
}statement 规则中有三个备选分支,但我们现在只需要一个。同样的,我们可以简单地将 AST 节点进一步传递下去。
method statement($/ where $<variable-declaration>) {
$/.make($<variable-declaration>.made);
}最后,在 TOP 层,创建 AST::TOP 节点,并将其 @.statements 填充到下面的节点中。
method TOP($/) {
my $top = AST::TOP.new;
for $<statement> -> $statement {
$top.statements.push($statement.made);
}
dd $top;
}为了查看生成的 AST 树的结构,添加了一些调试输出:dd $top。
将程序片段组装在一起,并对照本节开始的程序运行编译器。其顶部节点将包含以下数据。
AST::TOP $top = AST::TOP.new(statements => Array[ASTNode].new(AST::ScalarDeclaration.new(variable-name => "a", value => 0)))你可以看到一个数组的语句承载一个单一的语句,这是一个标量变量声明。这个变量被称为 a,它被设置为0。
让我们在程序中再加一行,并初始化这个变量。
my a;
my b = 2;所需的 AST 应该包含两个语句节点,其中第二个语句节点声明第二个变量 b 的初始值 2。

这次最好不要使用多方法,因为相对于方法本身的大小来说,scalar-declaration 方法的变化很小。对 $<value> 的检查是内联的:
method scalar-declaration($/) {
$/.make(AST::ScalarDeclaration.new(
variable-name => ~$<variable-name>,
value => $<value> ?? $<value>.made !! 0,
));
}本章的其余部分专门用于覆盖现有的语法和生成其他规则和令牌的 AST 节点。
8.3. 值节点
考虑做大一点的程序。
my c = 2 + 3;在这里,我们期望编译器生成的代码是加两个数。在这一点上我们没有考虑任何优化,所以我们必须为每一个算术运算生成 AST 节点。对比上一个 AST 树,我们可以看到 AST::ScalarDeclaration 节点的 value 属性不应该是一个裸数,而是其他一些代表加法的节点。为了保持设计的简单,明智的做法是引入 AST 注释,其唯一的工作就是保留值,可以是整数,也可以是浮点,或者是字符串。
class AST::NumberValue is ASTNode {
has $.value;
}如果没有值(如在没有初始化器的最小变量声明中),我们可以指定 0 或空字符串,但更好的解决方案是定义空值和它的封装器 AST 节点。
class AST::Null is ASTNode {
}AST::ScalarDeclaration 节点必须指向一个 AST 节点,所以让我们限制它的值属性类型。
class AST::ScalarDeclaration is ASTNode {
has Str $.variable-name;
has ASTNode $.value;
}我们在树上再增加两个 AST 节点,如下图所示。
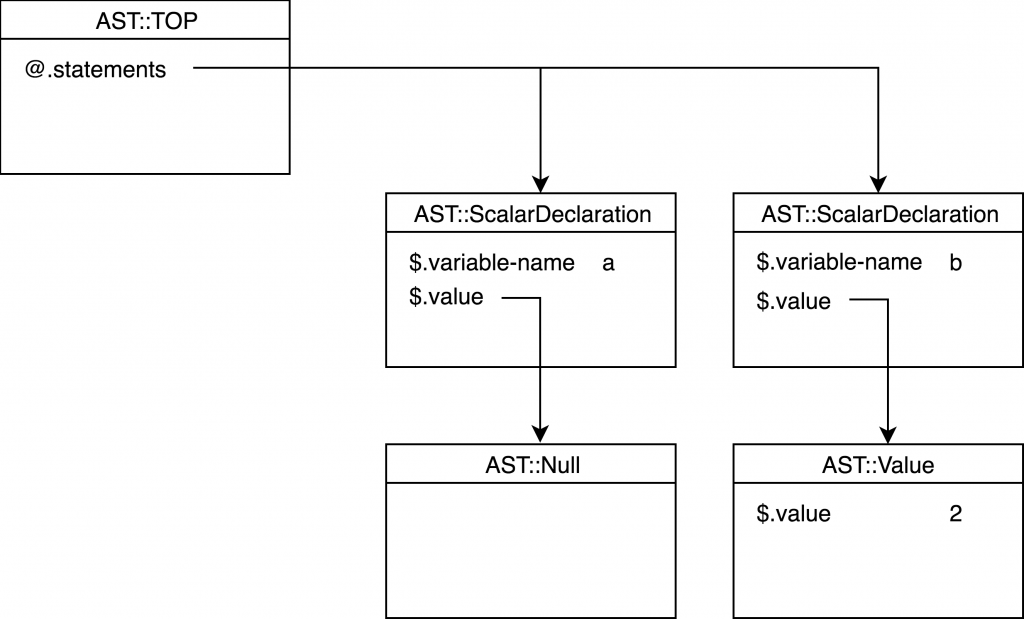
值节点必须由 grammar 中的 number 动作产生:
method number($/) {
$/.make(AST::NumberValue.new(value => +$/));
}这个节点在 scalar-declaration 方法中是按原样取的,但如果没有值,则创建一个 AST::Null 的副本。
method scalar-declaration($/) {
$/.make(AST::ScalarDeclaration.new(
variable-name => ~$<variable-name>,
value => $<value> ??
$<value>.made !!
AST::Null.new(),
));
}用另一个变量声明来扩展程序:
my c = b;这一次,我们得到的是一个变量,而不是一个值。但只要 AST::ScalarDeclaration 中的 $.value 属性的类型是 ASTNode,我们就可以创建一个新的类 AST::Variable,并保存一个实例。AST:::Variable 对象有一个字符串属性 $.variable-name。
class AST::Variable is ASTNode {
has Str $.variable-name;
}整合新的节点类型很容易,因为我们的大多数动作方法都有描述性签名。
multi method expr($/ where $<variable-name> && !$<index>) {
$/.make(AST::Variable.new(
variable-name => ~$<variable-name>));
}下面是结果 AST 树:
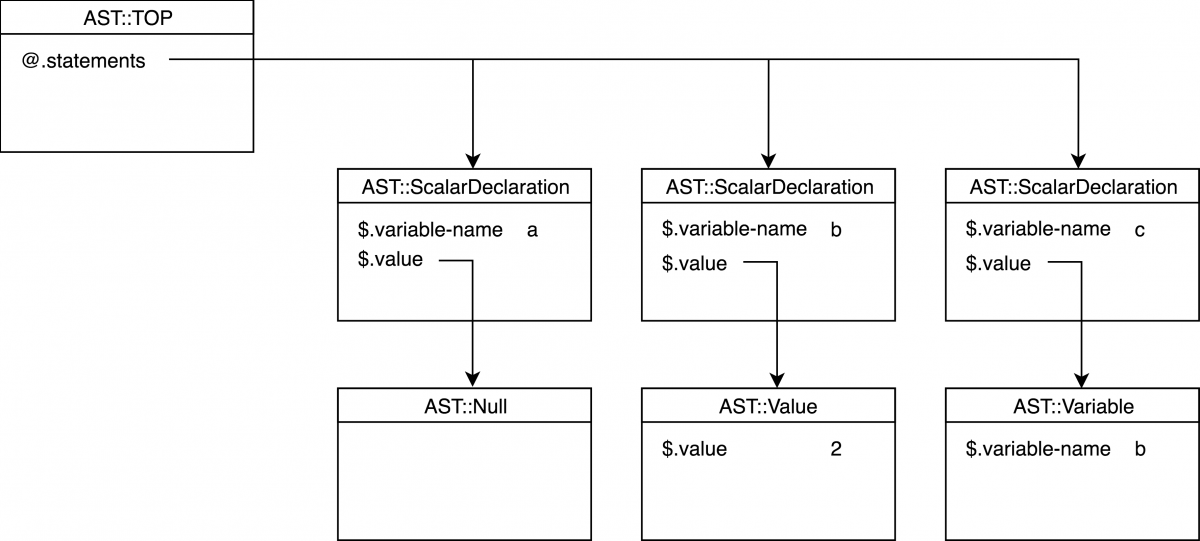
这棵树对应于下面的程序。
my a;
my b = 2;
my c = b;8.4. 声明字符串
对于字符串值,让我们创建一个新的节点类型 AST::StringValue。
class AST::StringValue is ASTNode {
has Str $.value;
}每当解析一个字符串,我们就会发出一个这个类的实例。
method string($a) {
. . .
$a.make(AST::StringValue.new(value => $s));
}我们将在下一章中返回到字符串,因为我们仍然需要重新实现变量插值。
8.5. 声明数组和散列
对于数组和哈希,我们还必须创建负责声明这些类型的变量的节点。让我们从数组开始。
class AST::ArrayDeclaration is ASTNode {
has Str $.variable-name;
has ASTNode @.elements;
}现在,让我们改变一下动作。目前,数组声明立即在 %!var 存储中创建一个槽:
multi method array-declaration($/ where !$<value>) {
%!var{$<variable-name>} = Array.new;
}当我们在处理 AST 树时,所有这些操作都必须推迟到编译器遍历完整的树后再进行。现在,唯一的操作就是进一步传递一个 AST:::ArrayDeclaration 节点。
multi method array-declaration($/ where !$) {
$/.make(AST::ArrayDeclaration.new(
variable-name => ~$,
elements => []
));
}新方法只是在树上增加了一个 AST 节点。
multi method variable-declaration($/ where $<array-declaration>) {
$/.make($<array-declaration>.made);
}
multi method array-declaration($/ where !$<value>) {
$/.make(AST::ArrayDeclaration.new(
variable-name => ~$<variable-name>,
elements => []));
}散列支持需要类似的代码,明显的区别在于元素属性的聚合类型。
multi method variable-declaration($/
where $<hash-declaration>) {
$/.make($<hash-declaration>.made);
}
multi method hash-declaration($/ where !$<string>) {
$/.make(AST::HashDeclaration.new(
variable-name => ~$<variable-name>,
elements => {}));
}AST 节点的定义如下所示:
class AST::HashDeclaration is ASTNode {
has Str $.variable-name;
has ASTNode %.elements;
}这个变化之后,你可能会发现有三种相似的方法。
multi method variable-declaration($/ where $<scalar-declaration>) {
$/.make($<scalar-declaration>.made);
}
multi method variable-declaration($/ where $<array-declaration>) {
$/.make($<array-declaration>.made);
}
multi method variable-declaration($/ where $<hash-declaration>) {
$/.make($<hash-declaration>.made);
}如果在 grammar 规则中加入别名,这三种方法都可以重写。
rule variable-declaration {
'my' [
| <declaration=array-declaration>
| <declaration=hash-declaration>
| <declaration=scalar-declaration>
]
}匹配变量现在包含两个条目:一个是原始规则名,第二个是别名。
「my array[]」
declaration => 「array[]」
variable-name => 「array」
array-declaration => 「array[]」
variable-name => 「array」有了这一点,这三个动作就可以合并成一个简单的单一方法,对规则的所有分支都能完成任务。
multi method variable-declaration($/) {
$/.make($<declaration>.made);
}8.6. 标量赋值
正如你所看到的,在构建 AST 的时候,我们要用前面几章中构建的所有规则来工作。实际上,我们需要在下一章中再来一轮,届时我们将创建代码来执行不同 AST 节点所需的动作。
现在,让我们先来实现标量分配。这个 AST 节点应该包含变量的名称和将被赋值的东西。让我们称它为 $.rhs,它代表右侧。这个对象肯定是 ASTNode,但我们不限制它到底承载什么东西。它可以是一个标量值,也可以是一个必须先被执行的表达式。
class AST::ScalarAssignment is ASTNode {
has Str $.variable-name;
has ASTNode $.rhs;
}与声明规则不同的是,只有一个赋值规则,我们用它的部分来调度动作方法。下面是为标量建立赋值节点需要修改的内容。
multi method assignment($/ where !$<index>) {
. . .
else {
$/.make(AST::ScalarAssignment.new(
variable-name => ~$<variable-name>,
rhs => $<value>[0].made));
}
}为了统一传递节点到语句中,我们可以用上一节中的小技巧,在规则中加入别名,统一传递节点到语句中。
rule statement {
| <statement=variable-declaration>
| <statement=assignment>
| <statement=function-call>
}现在,一个动作方法就可以处理三个分支。
method statement($/) {
$/.make($<statement>.made);
}8.7. 使用索引
重要的是,我们要意识到,当我们在建立 AST 时,并不是要立即对其进行计算。比如说,这意味着我们不应该担心一个变量的真实内容。我们的任务只是把它的名字放在节点的属性中。访问数组和哈希值元素也是一样的。在 AST 中,我们只保存变量的名称和元素的索引,如果变量是一个哈希,我们只保存变量的名称和索引。
让我们创建类来分配给数组和哈希项。
class AST::ArrayItemAssignment is ASTNode {
has Str $.variable-name;
has Int $.index;
has ASTNode $.rhs;
}
class AST::HashItemAssignment is ASTNode {
has Str $.variable-name;
has Str $.key;
has ASTNode $.rhs;
}一个数组的索引存储在一个整数的 $.index 字段中,而一个散列的键保存在字符串 $.key 中。在其他方面,节点的结构是一样的。
发出 AST 节点也是一项工作,对于数组和散列来说,看起来都是类似的。
multi method assignment($/
where $<index> && $<index><array-index>) {
$/.make(AST::ArrayItemAssignment.new(
variable-name => ~$<variable-name>,
index => $<index>.made,
rhs => $<value>[0].made
));
}
multi method assignment($/
where $<index> && $<index><hash-index>) {
$/.make(AST::HashItemAssignment.new(
variable-name => ~$<variable-name>,
key => $<index>.made.value,
rhs => $<value>[0].made
));
}请注意,使用 AST 节点已经让我们的赋值变得相当通用。例如,我们的代码既支持数字,也支持方程右侧的字符串。以下面的 Lingua 为例。
my a[];
a[2] = 3;
my b{};
b{"x"} = "y";其生成的 AST 树与节点所反映的代码行一起显示在下图中。

8.8. 数组和散列的赋值与初始化
我们跳过了初始化数组和哈希,这样做是有原因的。让我们先来做一下在两个不同的语句中声明和赋值的情况下的 AST,如下例所示。
my d[];
d = 3, 5, "7";
my e{};
e = "1": 2, "3": "4";数组和哈希分配与分配单个元素不同,所以这些操作需要自己的 AST 节点类型。
class AST::ArrayAssignment is ASTNode {
has Str $.variable-name;
has ASTNode @.elements;
}
class AST::HashAssignment is ASTNode {
has Str $.variable-name;
has Str @.keys;
has ASTNode @.values;
}对于数组,我们收集由一些 AST 节点组成的数组中的元素。对于哈希数组,键和值被保存在不同的数组中,并且键被强制为字符串。或者,我们可以创建 Pair 对象(Pair 是 Raku 的内置类型)来组合键值对。
在操作中,我们必须仔细地将标量、数组和散列的赋值分开。多方法在这里工作得很好,而在 where 子句中可能需要很多条件。另一种方法是将 assignment 规则分成三个,每个数据类型一个。总之,这里是我们目前的动作方法的实现。
multi method assignment($/ where !$<index> &&
!$<value>) {
$/.make(AST::ScalarAssignment.new(
variable-name => ~$<variable-name>,
rhs => $<value>[0].made
));
}
multi method assignment($/ where !$<index> &&
$<value> &&
!$<string>) {
$/.make(AST::ArrayAssignment.new(
variable-name => ~$<variable-name>,
elements => $<value>.map: *.made
));
}
multi method assignment($/ where !$<index> &&
$<value> &&
$<string>) {
$/.make(AST::HashAssignment.new(
variable-name => ~$<variable-name>,
keys => ($<string>.map: *.made.value),
values => ($<value>.map: *.made)
));
}仔细研究一下这段代码:你应该明白方法签名是如何帮助在每个给定情况下选择合适的方法的。在这段代码中,也使用了很多 map 方法,它们总是很简洁,大部分都很清晰,但是写起来却不容易。
下一步就是完成任务的初始化动作,我们已经有了初始化动作的代码。将其提取到独立的函数中(就像我们之前在解释器中所做的那样),最后的结果是这样的。
数组相关的方法。
sub init-array($variable-name, $elements) {
return AST::ArrayAssignment.new(
variable-name => $variable-name,
elements => $elements.map: *.made
);
}
multi method array-declaration($/ where $<value>) {
$/.make(init-array(~$<variable-name>, $<value>));
}
multi method assignment($/ where !$<index> && $<value> && !$<string>) {
$/.make(init-array(~$<variable-name>, $<value>));
}这段代码看起来又是透明的,不言自明。对哈希相关的代码重复同样的操作。
sub init-hash($variable-name, $keys, $values) {
return AST::HashAssignment.new(
variable-name => $variable-name,
keys => ($keys.map: *.made.value),
values => ($values.map: *.made)
);
}
multi method hash-declaration($/ where $<string> && $<value>) {
$/.make(init-hash(~$<variable-name>,
$<string>, $<value>));
}
multi method assignment($/ where !$<index> && $<value> && $<string>) {
$/.make(init-hash(~$<variable-name>,
$<string>, $<value>));
}现在很多语法规则都已经涵盖了。让我们继续填补新的编译器架构中的空白,实现表达式和函数调用的 AST 元素。我们的目标是,我们的目标是,有的动作方法只是将 made 的值传递给下一级,有的动作方法则是将 AST::* 对象中的一个放到 made 属性中。
8.9. AST 表达式
考虑一个简单的程序。
my a;
a = 2 + 3;第一行是一个变量的声明,第二行是赋值。这里还有一个动作:加法,这也必须用一个AST节点来表示。让我们建立下面的树。
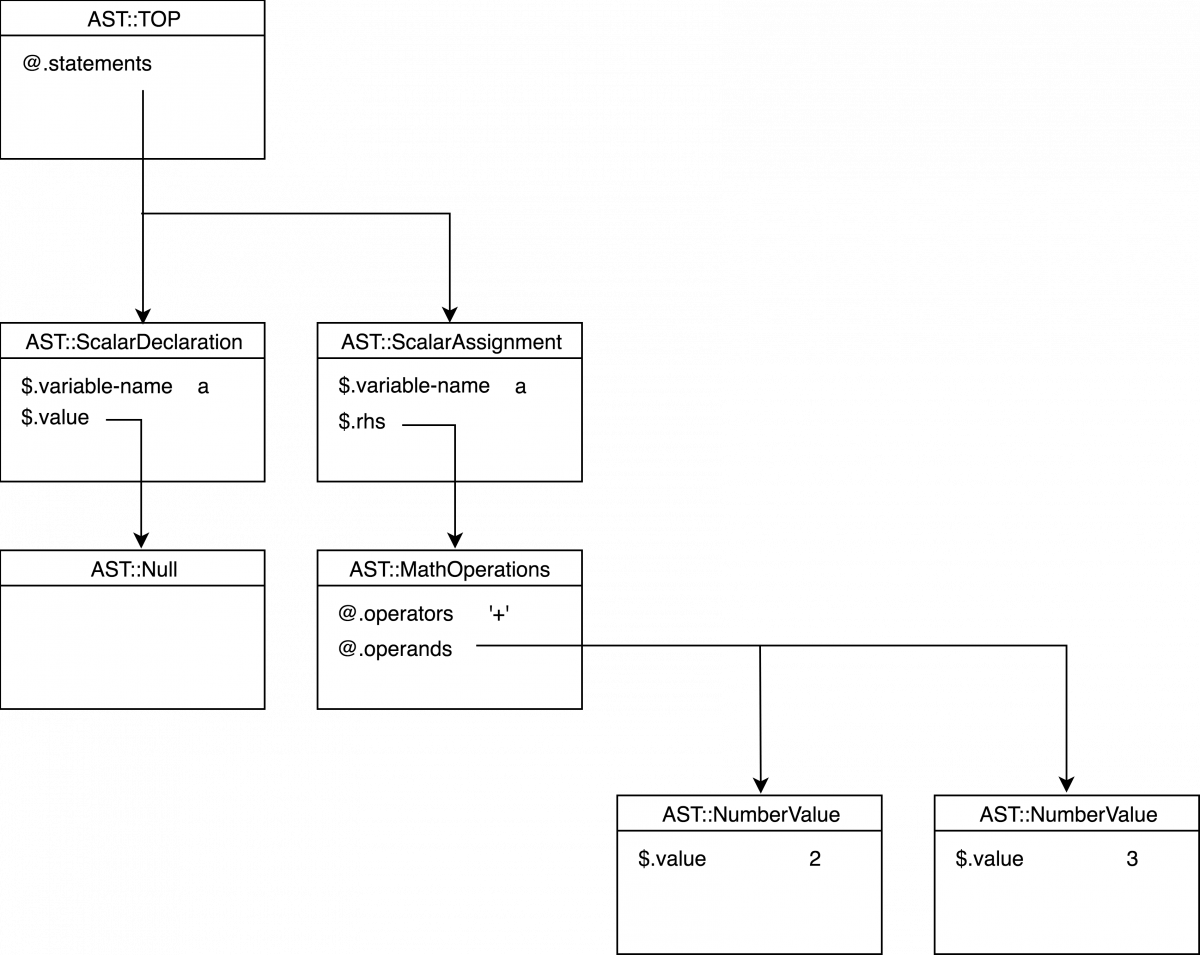
你可能会注意到,新的节点叫做 AST:::MathOperations,它包含两个数组,分别是运算符和操作数组。
在最简单的例子中,只有一个运算符和两个运算符,但同样的对象也适用于较长的序列,例如 2 + 3 - 4,所有的运算符都有相同的优先级。这样的解决方案有助于减少 AST 节点的数量,同时也简化了下一步处理树的过程。
所以,下面是类。
class AST::MathOperations is ASTNode {
has Str @.operators;
has ASTNode @.operands;
}操作符以字符串的形式存储;操作子是其他 AST 节点。将 AST 生成嵌入到 LinguaActions 类中的 AST 生成有更多的删除量而不是插入量。我们必须删除所有的 operation 子程序。它们做实际的加法、乘法等操作,而我们在 AST 中不需要这些。所有这些实际的操作都将在后期的遍历树上完成。
有几个多变体的 expr 动作,在一边,这种理念使得实现起来更加困难,因为你必须考虑到 AST 节点将如何传播到最上面的 AST 节点。另一方面,你可以把它拆成更小的动作,根据匹配对象中的 $<op> 键的存在,决定是否要发出一个 AST:::MathOperations 或 AST:::NumberValue 节点。换句话说,如果表达式中存在运算符,就使用 AST:::MathOperations,否则就产生一个存储在 AST:::NumberValue 节点属性中的数字。
multi method expr($/ where $<expr> && !$<op>) {
$/.make($<expr>[0].made);
}
multi method expr($/ where $<expr> && $<op>) {
$/.make(AST::MathOperations.new(
operators => ($<op>.map: ~*),
operands => ($<expr>.map: *.made)
));
}
multi method expr($/ where $<expression>) {
$/.make($<expression>.made);
}我们的实现不是一个标准的算术表达式的 AST 树。让我们来考察一个简单的表达式,其中有不同优先级的运算符。
my x = 2 + 3 * 4 / 5 - 6;在其他关于编译器设计和解析的书中,你很可能会遇到这样一棵树,每个节点代表一个有两个运算符的单项运算,如下图左侧所示。
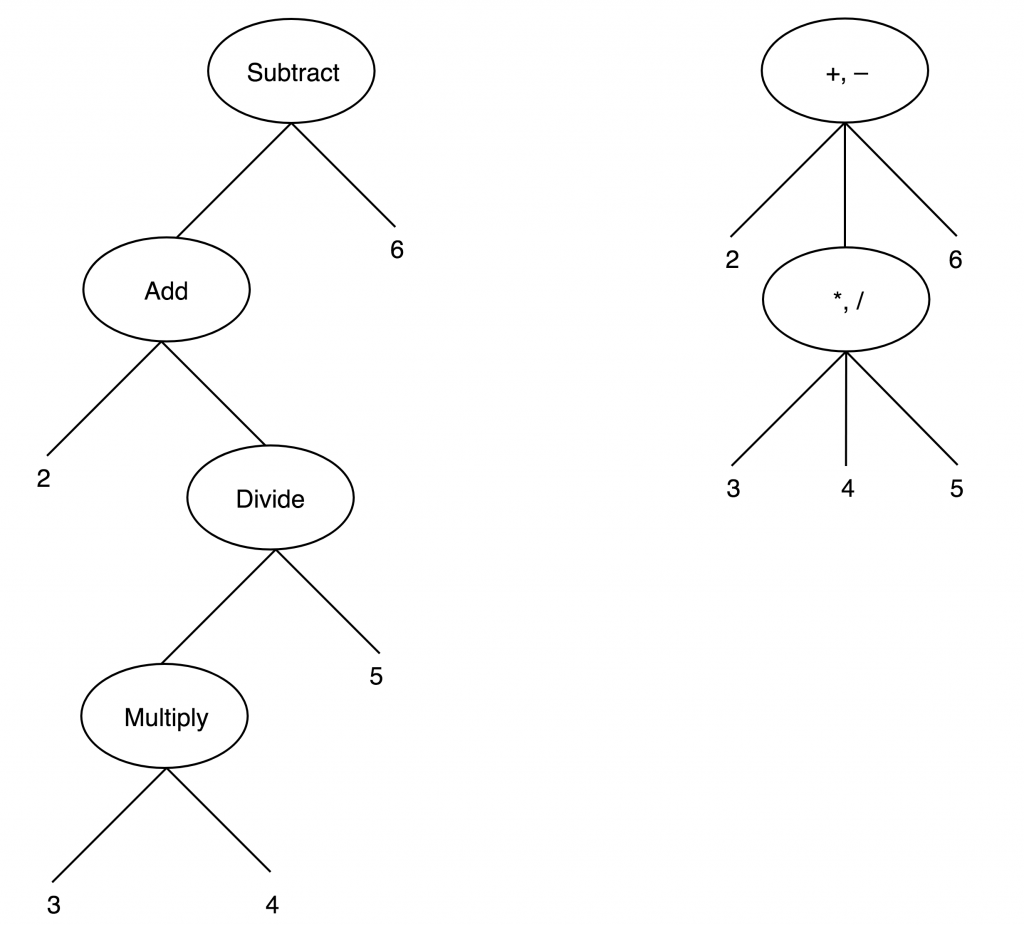
我们的编译器的树形图如右图所示。每个节点可以接受任意数量的操作符,而且树的结构更加紧凑:在这个例子中,与标准版本相比,节点数量是标准版本的2倍。如果节点有三个操作符,那么它应该有两个操作符,以后你将把它们放在操作符之间。
树建立好后,TOP 方法中的 $top 变量包含以下数据结构。
AST::TOP $top = AST::TOP.new(
statements => Array[ASTNode].new(
AST::ScalarDeclaration.new(
variable-name => "x",
value => AST::MathOperations.new(
operators => Array[Str].new(
"+",
"-"
),
operands => Array[ASTNode].new(
AST::NumberValue.new(
value => 2
),
AST::MathOperations.new(
operators => Array[Str].new(
"*",
"/"
),
operands => Array[ASTNode].new(
AST::NumberValue.new(
value => 3
),
AST::NumberValue.new(
value => 4
),
AST::NumberValue.new(
value => 5
)
)
),
AST::NumberValue.new(
value => 6
)
)
)
)
)
)8.10. 函数调用
函数调用的形式也大大简化了 AST,因为节点只携带函数的名称和包含函数参数的节点。
class AST::FunctionCall is ASTNode {
has Str $.function-name;
has ASTNode $.value;
}新的动作方法不做任何真正的打印或字符串格式化。
method function-call($/) {
$/.make(AST::FunctionCall.new(
function-name => ~$<function-name>,
value => $<value>.made
));
}8.11. 最终的调优
在本章的最后,让我们做一些改动,让我们有了一个更简单的 AST。这在早期并不是那么重要,但现在我们可以看到一个真正的解析树了。让我们在值规则中增加一个变量名称的快捷方式。目前,变量的名字应该是从最深的 expr(4) 规则中冒出来的。我们可以让解析器立即看到它。
rule value {
| <variable-name>
| <expression>
| <string>
}因此,这个动作,立即创建了 AST:::Variable 节点。
multi method value($/ where $<variable-name>) {
$/.make(AST::Variable.new(
variable-name => ~$<variable-name>
));
}最好是用可选的索引来扩展变量名称,以允许数组和哈希值中的元素。
rule value {
| <variable-name> <index>?
| <expression>
| <string>
}我们还需要为这类数据定义 AST 节点。
class AST::ArrayItem is ASTNode {
has Str $.variable-name;
has ASTNode $.index;
}
class AST::HashItem is ASTNode {
has Str $.variable-name;
has ASTNode $.key;
}我们使用 ASTNode 类型来存储数组索引和哈希键的原因是,我们希望它们不仅是整数或字符串,而且是其他变量。
my c{} = "a": 1, "b": 2;
my s = "a";
say c{s};纠正现有的动作,再增加几个动作:
multi method value($/ where $<variable-name> && !$<index>) {
$/.make(AST::Variable.new(
variable-name => ~$<variable-name>
));
}
multi method value($/ where $<variable-name> && $<index> &&
$<index><array-index>) {
$/.make(AST::ArrayItem.new(
variable-name => ~$<variable-name>,
index => $<index>.made
));
}
multi method value($/ where $<variable-name> && $<index> &&
$<index><hash-index>) {
$/.make(AST::HashItem.new(
variable-name => ~$<variable-name>,
key => $<index>.made
));
}指数本身需要转换为 AST 节点。对于每一种索引,根据我们是否看到变量,有两种多方法。
multi method array-index($/ where !$<variable-name>) {
$/.make(AST::NumberValue.new(
value => +$<integer>
));
}
multi method array-index($/ where $<variable-name>) {
$/.make(AST::Variable.new(
variable-name => ~$<variable-name>
));
}
multi method hash-index($/ where !$<variable-name>) {
$/.make($<string>.made);
}
multi method hash-index($/ where $<variable-name>) {
$/.make(AST::Variable.new(
variable-name => ~$<variable-name>
));
}另一个需要我们担心变量的地方是,还有一个部分还是由旧动作管理的部分。
multi method expr($/ where $<variable-name> && $<index>) {
if %!var{$<variable-name>} ~~ Array {
$/.make(%!var{$<variable-name>}[$<index>.made]);
}
elsif %!var{$<variable-name>} ~~ Hash {
$/.make(%!var{$<variable-name>}{$<index>.made});
}
else {
$/.make(%!var{$<variable-name>}.substr($<index>.made, 1));
}
}这段代码会检查手边的变量类型,并决定如何处理这个变量。正如我们之前在本章中已经做过的那样,我们将删除所有这些逻辑,取而代之的是 AST 节点中的一个节点,这不是取决于变量的类型,而是取决于此时的语法信息。
multi method expr($/ where $<variable-name> && !$<index>) {
$/.make(AST::Variable.new(
variable-name => ~$<variable-name>
));
}
multi method expr($/ where $<variable-name> && $<index> &&
$<index><array-index>) {
$/.make(AST::ArrayItem.new(
variable-name => ~$<variable-name>,
index => $<index>.made
));
}
multi method expr($/ where $<variable-name> && $<index> &&
$<index><hash-index>) {
$/.make(AST::HashItem.new(
variable-name => ~$<variable-name>,
key => $<index>.made.value
));
}作为一个家庭作业,可以尝试修改一下语法,以消除有变量快捷键的需要(你也会希望把上面的代码与我们在本节中看到的 value 方法结合起来。
最后,让我们修改动作,以便在下面的作业中更加小心翼翼地进行修正。
my a;
my b[];
a = 1;
b = 1, 2, 3;在我们不知道变量的类型之前,判断赋值中的变量是数组还是标量的唯一方法就是计算等号右边的元素。下面是我们的方法。
multi method assignment($/ where !$<index> && $<value> && !$<string>) {
if $<value>.elems == 1 {
$/.make(AST::ScalarAssignment.new(
variable-name => ~$<variable-name>,
rhs => $<value>[0].made
));
}
else {
$/.make(AST::ArrayAssignment.new(
variable-name => ~$<variable-name>,
elements => ($<value>.map: *.made)
));
}
}现在就到此为止。在这一章中,也是全书最大的一章,我们走了很远的路,将编译器从一个解释器转变为一个构建抽象语法树的机器。正如你刚才看到的那样,我们去掉了一些代码,大多时候只能依靠语法。尽管如此,所得到的树还是很好地表示了程序的流程,我们很快就会有效地使用它。
8.12. 声明字符串
对于字符串值, 让我们 来创建一种新的节点类型, 即 AST::StringValue:
class AST::StringValue is ASTNode {
has Str $.value;
}每当解析一个字符串,我们就会发出一个这个类的实例:
method string($a) {
. . .
$a.make(AST::StringValue.new(value => $s));
}我们将在下一章中返回到字符串,因为我们仍然需要重新实现变量插值。
8.13. 声明数组和散列
对于数组和散列,我们还必须创建负责声明这些类型的变量的节点。让我们从数组开始:
class AST::ArrayDeclaration is ASTNode {
has Str $.variable-name;
has ASTNode @.elements;
}现在,让我们改变一下 action。目前,数组声明立即在 %!var 存储中创建一个槽:
multi method array-declaration($/ where !$<value>) {
%!var{$<variable-name>} = Array.new;
}当我们在处理 AST 树时,所有这些 action 都必须推迟到编译器遍历完整的树后再进行。现在,唯一的 action 就是进一步传递一个 AST:::ArrayDeclaration 节点:
multi method array-declaration($/ where !$) {
$/.make(AST::ArrayDeclaration.new(
variable-name => ~$,
elements => []
));
}这个新方法只是在树上增加了一个 AST 节点。
multi method variable-declaration($/ where $<array-declaration>) {
$/.make($<array-declaration>.made);
}
multi method array-declaration($/ where !$<value>) {
$/.make(AST::ArrayDeclaration.new(
variable-name => ~$<variable-name>,
elements => []));
}散列支持需要类似的代码,明显的区别在于元素属性的聚合类型。
multi method variable-declaration($/
where $<hash-declaration>) {
$/.make($<hash-declaration>.made);
}
multi method hash-declaration($/ where !$<string>) {
$/.make(AST::HashDeclaration.new(
variable-name => ~$<variable-name>,
elements => {}));
}AST 节点的定义如下所示:
class AST::HashDeclaration is ASTNode {
has Str $.variable-name;
has ASTNode %.elements;
}这个变化之后,你可能会发现有三个相似的方法:
multi method variable-declaration($/ where $<scalar-declaration>) {
$/.make($<scalar-declaration>.made);
}
multi method variable-declaration($/ where $<array-declaration>) {
$/.make($<array-declaration>.made);
}
multi method variable-declaration($/ where $<hash-declaration>) {
$/.make($<hash-declaration>.made);
}如果在 grammar 的 rule 中加入别名,这三个方法都可以被重写:
rule variable-declaration {
'my' [
| <declaration=array-declaration>
| <declaration=hash-declaration>
| <declaration=scalar-declaration>
]
}匹配变量现在包含两个条目:一个是原始规则名,第二个是别名:
「my array[]」
declaration => 「array[]」
variable-name => 「array」
array-declaration => 「array[]」
variable-name => 「array」有了这一点,这三个 action 就可以合并成一个简单的单一方法,对规则的所有分支都能完成任务。
multi method variable-declaration($/) {
$/.make($<declaration>.made);
}8.14. 标量赋值
正如你所看到的,在构建 AST 的时候,我们要用前面几章中构建的所有规则来工作。实际上,我们需要在下一章中再来一轮,届时我们将创建代码来执行不同 AST 节点所需的动作。
现在,让我们先来实现标量分配。这个 AST 节点应该包含变量的名称和将被赋值的东西。让我们称它为 $.rhs,它代表右侧。这个对象肯定是 ASTNode,但我们不限制它到底承载什么东西。它可以是一个标量值,也可以是一个必须先被执行的表达式。
class AST::ScalarAssignment is ASTNode {
has Str $.variable-name;
has ASTNode $.rhs;
}与声明规则不同的是,只有一个赋值规则,我们用它的部分来调度动作方法。下面是为标量建立赋值节点需要修改的内容。
multi method assignment($/ where !$<index>) {
. . .
else {
$/.make(AST::ScalarAssignment.new(
variable-name => ~$<variable-name>,
rhs => $<value>[0].made));
}
}为了统一传递节点到语句中,我们可以用上一节中的小技巧,在规则中加入别名,统一传递节点到语句中。
rule statement {
| <statement=variable-declaration>
| <statement=assignment>
| <statement=function-call>
}现在,一个 action 方法就可以处理三个分支:
method statement($/) {
$/.make($<statement>.made);
}8.15. 处理索引
重要的是,我们要意识到,当我们在建立 AST 时,并不是要立即对其进行计算。比如说,这意味着我们不应该担心一个变量的真实内容。我们的任务只是把它的名字放在节点的属性中。访问数组和散列的元素也是一样的。在 AST 中,我们只保存变量的名称和元素的索引,如果变量是一个散列,我们只保存变量的名称和索引。
让我们创建类来赋值给数组和散列项。
class AST::ArrayItemAssignment is ASTNode {
has Str $.variable-name;
has Int $.index;
has ASTNode $.rhs;
}
class AST::HashItemAssignment is ASTNode {
has Str $.variable-name;
has Str $.key;
has ASTNode $.rhs;
}数组的索引存储在一个整型的 $.index 字段中,而一个散列的键保存在字符串 $.key 中。在其他方面,节点的结构是一样的。
发出 AST 节点也是一项工作,对于数组和散列来说,看起来都是类似的:
multi method assignment($/
where $<index> && $<index><array-index>) {
$/.make(AST::ArrayItemAssignment.new(
variable-name => ~$<variable-name>,
index => $<index>.made,
rhs => $<value>[0].made
));
}
multi method assignment($/
where $<index> && $<index><hash-index>) {
$/.make(AST::HashItemAssignment.new(
variable-name => ~$<variable-name>,
key => $<index>.made.value,
rhs => $<value>[0].made
));
}请注意,使用 AST 节点已经让我们的赋值变得相当通用。例如,我们的代码既支持数字,也支持方程右侧的字符串。以下面的 Lingua 为例:
my a[];
a[2] = 3;
my b{};
b{"x"} = "y";其生成的 AST 树与节点所反映的代码行一起显示在下图中。

8.16. 数组和散列的赋值与初始化
我们跳过了初始化数组和散列,这样做是有原因的。让我们先来做一下在两个不同的语句中声明和赋值的情况下的 AST,如下例所示:
my d[];
d = 3, 5, "7";
my e{};
e = "1": 2, "3": "4";数组和散列赋值与分配单个元素不同,所以这些 action 需要自己的 AST 节点类型:
class AST::ArrayAssignment is ASTNode {
has Str $.variable-name;
has ASTNode @.elements;
}
class AST::HashAssignment is ASTNode {
has Str $.variable-name;
has Str @.keys;
has ASTNode @.values;
}对于数组,我们收集由一些 AST 节点组成的数组中的元素。对于散列数组,键和值被保存在不同的数组中,并且键被强制为字符串。或者,我们可以创建 Pair 对象(Pair 是 Raku 的内置类型)来组合键值对。
在 action 中,我们必须仔细地将标量、数组和散列的赋值分开。Multi 方法在这里工作得很好,而在 where 子句中可能需要很多条件。另一种方法是将赋值规则分成三个,每个数据类型一个。总之,这里是我们目前的 action 方法的实现:
multi method assignment($/ where !$<index> &&
!$<value>) {
$/.make(AST::ScalarAssignment.new(
variable-name => ~$<variable-name>,
rhs => $<value>[0].made
));
}
multi method assignment($/ where !$<index> &&
$<value> &&
!$<string>) {
$/.make(AST::ArrayAssignment.new(
variable-name => ~$<variable-name>,
elements => $<value>.map: *.made
));
}
multi method assignment($/ where !$<index> &&
$<value> &&
$<string>) {
$/.make(AST::HashAssignment.new(
variable-name => ~$<variable-name>,
keys => ($<string>.map: *.made.value),
values => ($<value>.map: *.made)
));
}仔细研究一下这段代码:你应该明白方法签名是如何帮助在每个给定情况下选择合适的方法的。在这段代码中,也使用了很多 map 方法,它们总是很简洁,大部分都很清晰,但是写起来却不容易。
下一步就是使用初始化 action 完成赋值,我们已经有了初始化 action 的代码。将其提取到独立的函数中(就像我们之前在解释器中所做的那样),最后的结果是这样的。
数组相关的方法:
sub init-array($variable-name, $elements) {
return AST::ArrayAssignment.new(
variable-name => $variable-name,
elements => $elements.map: *.made
);
}
multi method array-declaration($/ where $<value>) {
$/.make(init-array(~$<variable-name>, $<value>));
}
multi method assignment($/ where !$<index> && $<value> && !$<string>) {
$/.make(init-array(~$<variable-name>, $<value>));
}这段代码看起来又是透明的,不言自明。对散列相关的代码重复同样的操作:
sub init-hash($variable-name, $keys, $values) {
return AST::HashAssignment.new(
variable-name => $variable-name,
keys => ($keys.map: *.made.value),
values => ($values.map: *.made)
);
}
multi method hash-declaration($/ where $<string> && $<value>) {
$/.make(init-hash(~$<variable-name>,
$<string>, $<value>));
}
multi method assignment($/ where !$<index> && $<value> && $<string>) {
$/.make(init-hash(~$<variable-name>,
$<string>, $<value>));
}现在很多 grammar 规则都已经涵盖了。让我们继续填补新的编译器架构中的空白,实现表达式和函数调用的 AST 元素。我们的目标是,我们的目标是,有的动作方法只是将 made 的值传递给下一级,有的 action 方法则是将 AST::* 对象中的一个放到 made 属性中。
8.17. AST 表达式
考虑一个简单的程序:
my a;
a = 2 + 3;第一行是一个变量的声明,第二行是赋值。这里还有一个 action:加法,这也必须用一个 AST 节点来表示。让我们建立下面的树。
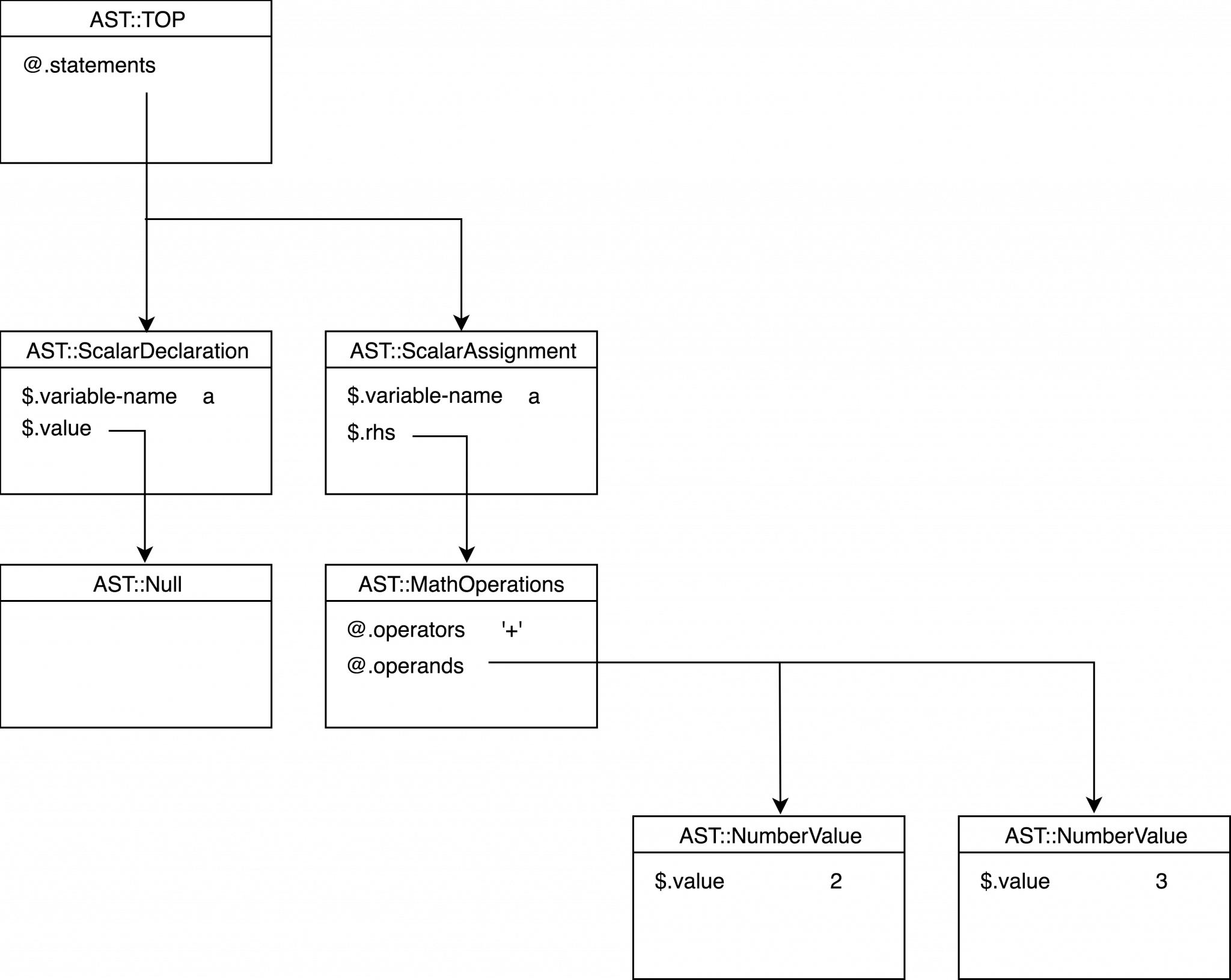
你可能会注意到,新的节点叫做 AST::MathOperations,它包含两个数组,分别是运算符和操作数组。
在最简单的例子中,只有一个运算符和两个运算符,但同样的对象也适用于较长的序列,例如 2 + 3 - 4,所有的运算符都有相同的优先级。这样的解决方案有助于减少 AST 节点的数量,同时也简化了下一步处理树的过程。
所以,下面是类:
class AST::MathOperations is ASTNode {
has Str @.operators;
has ASTNode @.operands;
}操作符以字符串的形式存储;操作子是其他 AST 节点。将 AST 生成嵌入到 LinguaActions 类中的 AST 生成有更多的删除量而不是插入量。我们必须删除所有的操作子程序。它们做实际的加法、乘法等操作,而我们在 AST 中不需要这些。所有这些实际的操作都将在后期的遍历树上完成。
有几个多变体的 expr 动作,在一边,这种理念使得实现起来更加困难,因为你必须考虑到 AST 节点将如何传播到最上面的 AST 节点。另一方面,你可以把它拆成更小的动作,根据匹配对象中的 $<op> 键的存在,决定是否要发出一个 AST::MathOperations 或 AST::NumberValue 节点。换句话说,如果表达式中存在运算符,就使用 AST::MathOperations,否则就产生一个存储在 AST::NumberValue 节点属性中的数字。
multi method expr($/ where $<expr> && !$<op>) {
$/.make($<expr>[0].made);
}
multi method expr($/ where $<expr> && $<op>) {
$/.make(AST::MathOperations.new(
operators => ($<op>.map: ~*),
operands => ($<expr>.map: *.made)
));
}
multi method expr($/ where $<expression>) {
$/.make($<expression>.made);
}我们的实现不是一个标准的算术表达式的 AST 树。让我们来考察一个简单的表达式,其中有不同优先级的运算符。
my x = 2 + 3 * 4 / 5 - 6;在其他关于编译器设计和解析的书中,你很可能会遇到这样一棵树,每个节点代表一个有两个运算符的单项运算,如下图左侧所示。
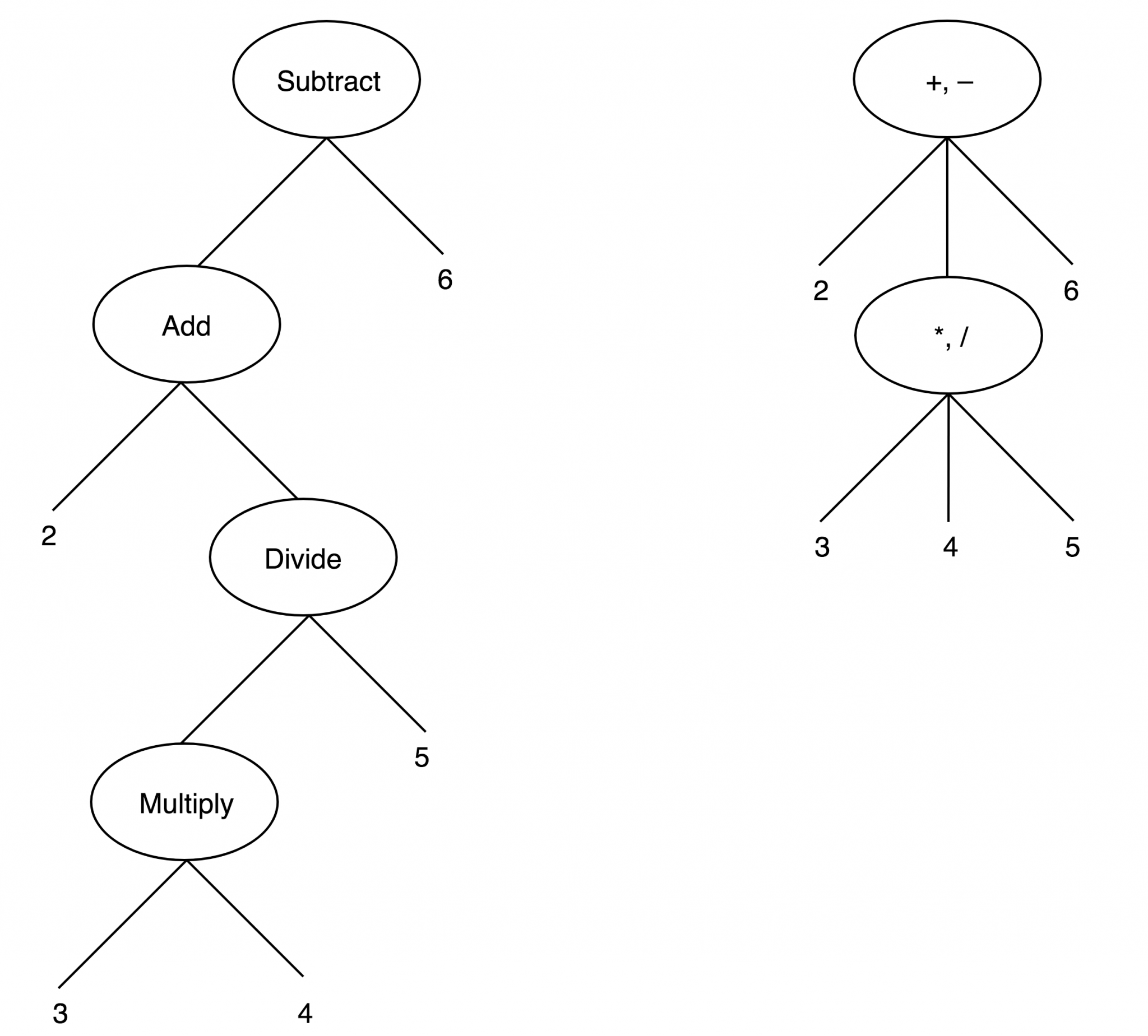
我们的编译器的树形图如右图所示。每个节点可以接受任意数量的操作符,而且树的结构更加紧凑:在这个例子中,与标准版本相比,节点数量是标准版本的2倍。如果节点有三个操作符,那么它应该有两个操作符,以后你将把它们放在操作符之间。
树建立好后,TOP 方法中的 $TOP 变量包含以下数据结构:
AST::TOP $top = AST::TOP.new(
statements => Array[ASTNode].new(
AST::ScalarDeclaration.new(
variable-name => "x",
value => AST::MathOperations.new(
operators => Array[Str].new(
"+",
"-"
),
operands => Array[ASTNode].new(
AST::NumberValue.new(
value => 2
),
AST::MathOperations.new(
operators => Array[Str].new(
"*",
"/"
),
operands => Array[ASTNode].new(
AST::NumberValue.new(
value => 3
),
AST::NumberValue.new(
value => 4
),
AST::NumberValue.new(
value => 5
)
)
),
AST::NumberValue.new(
value => 6
)
)
)
)
)
)8.18. 函数调用
函数调用的形式也大大简化了 AST,因为节点只携带函数的名称和包含函数参数的节点。
class AST::FunctionCall is ASTNode {
has Str $.function-name;
has ASTNode $.value;
}新的 action 方法不做任何真正的打印或字符串格式化。
method function-call($/) {
$/.make(AST::FunctionCall.new(
function-name => ~$<function-name>,
value => $<value>.made
));
}8.19. 最后的调试
在本章的最后,让我们做一些改动,让我们有了一个更简单的 AST。这在早期并不是那么重要,但现在我们可以看到一个真正的解析树了。让我们在值规则中增加一个变量名称的快捷方式。目前,变量的名字应该是从最深的 expr(4) 规则中冒出来的。我们可以让解析器立即看到它。
rule value {
| <variable-name>
| <expression>
| <string>
}因此,这个 action,立即创建了 AST:::Variable 节点。
multi method value($/ where $<variable-name>) {
$/.make(AST::Variable.new(
variable-name => ~$<variable-name>
));
}最好是用可选的索引来扩展变量名称,以允许数组和哈散列中的元素。
rule value {
| <variable-name> <index>?
| <expression>
| <string>
}我们还需要为这类数据定义 AST 节点。
class AST::ArrayItem is ASTNode {
has Str $.variable-name;
has ASTNode $.index;
}
class AST::HashItem is ASTNode {
has Str $.variable-name;
has ASTNode $.key;
}我们使用 ASTNode 类型来存储数组索引和散列键的原因是,我们希望它们不仅是整数或字符串,而且是其他变量。
my c{} = "a": 1, "b": 2;
my s = "a";
say c{s};纠正现有的 action,再增加几个 action。
multi method value($/ where $<variable-name> && !$<index>) {
$/.make(AST::Variable.new(
variable-name => ~$<variable-name>
));
}
multi method value($/ where $<variable-name> && $<index> &&
$<index><array-index>) {
$/.make(AST::ArrayItem.new(
variable-name => ~$<variable-name>,
index => $<index>.made
));
}
multi method value($/ where $<variable-name> && $<index> &&
$<index><hash-index>) {
$/.make(AST::HashItem.new(
variable-name => ~$<variable-name>,
key => $<index>.made
));
}索引本身需要转换为 AST 节点。对于每一种索引,根据我们是否看到变量,有两种多方法。
multi method array-index($/ where !$<variable-name>) {
$/.make(AST::NumberValue.new(
value => +$<integer>
));
}
multi method array-index($/ where $<variable-name>) {
$/.make(AST::Variable.new(
variable-name => ~$<variable-name>
));
}
multi method hash-index($/ where !$<variable-name>) {
$/.make($<string>.made);
}
multi method hash-index($/ where $<variable-name>) {
$/.make(AST::Variable.new(
variable-name => ~$<variable-name>
));
}另一个需要我们担心变量的地方是,还有一个部分还是由旧 action 管理的部分。
multi method expr($/ where $<variable-name> && $<index>) {
if %!var{$<variable-name>} ~~ Array {
$/.make(%!var{$<variable-name>}[$<index>.made]);
}
elsif %!var{$<variable-name>} ~~ Hash {
$/.make(%!var{$<variable-name>}{$<index>.made});
}
else {
$/.make(%!var{$<variable-name>}.substr($<index>.made, 1));
}
}这段代码会检查手边的变量类型,并决定如何处理这个变量。正如我们之前在本章中已经做过的那样,我们将删除所有这些逻辑,取而代之的是 AST 节点中的一个节点,这不是取决于变量的类型,而是取决于此时的语法信息。
multi method expr($/ where $<variable-name> && !$<index>) {
$/.make(AST::Variable.new(
variable-name => ~$<variable-name>
));
}
multi method expr($/ where $<variable-name> && $<index> &&
$<index><array-index>) {
$/.make(AST::ArrayItem.new(
variable-name => ~$<variable-name>,
index => $<index>.made
));
}
multi method expr($/ where $<variable-name> && $<index> &&
$<index><hash-index>) {
$/.make(AST::HashItem.new(
variable-name => ~$<variable-name>,
key => $<index>.made.value
));
}作为一个家庭作业,可以尝试修改一下语法,以消除有变量快捷键的需要(你也会希望把上面的代码与我们在本节中看到的 `value`方法结合起来)。
最后,让我们修改 action,以便在下面的作业中更加小心翼翼地进行修正。
my a;
my b[];
a = 1;
b = 1, 2, 3;在我们不知道变量的类型之前,判断赋值中的变量是数组还是标量的唯一方法就是计算等号右边的元素。下面是我们的方法。
multi method assignment($/ where !$<index> && $<value> && !$<string>) {
if $<value>.elems == 1 {
$/.make(AST::ScalarAssignment.new(
variable-name => ~$<variable-name>,
rhs => $<value>[0].made
));
}
else {
$/.make(AST::ArrayAssignment.new(
variable-name => ~$<variable-name>,
elements => ($<value>.map: *.made)
));
}
}现在就到此为止。在这一章中,也是全书最大的一章,我们走了很远的路,将编译器从一个解释器转变为一个构建抽象语法树的机器。正如你刚才看到的那样,我们去掉了一些代码,大多时候只能依靠 grammar。尽管如此,所得到的树还是很好地表示了程序的流程,我们很快就会有效地使用它。
9. 计算 AST
在上一章中, 我们学习了如何将输入程序转化为 AST。这个树只保存了程序的实际本质信息, 而忽略了比如说源代码中的所有注释。
在整个上一章的学习过程中, 编译器的输出就是一棵树。我们可以看到程序认为它要做什么, 但实际上我们并没有看到这个工作的结果。在这一章中, 我们将遍历 AST 并执行它所代表的任务。
9.1. 从 top 开始计算
AST 树的元素从叶子规则和令牌冒泡到 TOP 规则。让我们让我们的返回 AST 的 grammar。
method TOP($/) {
my $top = AST::TOP.new;
. . .
$/.make($top);
}当我们在构建树的时候, make 和 made 这对方法给了我们传递树片段到父节点的方法。当你在 TOP 层使用 make 时, 你得到的对象是解析方法的结果。
my $ast = Lingua.parse($code, :actions(LinguaActions.new));
say $ast ?? 'OK' !! error('Error: parse failed');我们在布尔语境中使用了生成的 AST, 但这并不是我们唯一能用它做的事情。在本章中, 我们将致力于创建沿着树上行走的代码, 并执行节点要求的动作。
在主脚本中, 让我们将 AST 传递给 LinguaEvaluator 类的一些 eval 方法(我们要创建它)。
use LinguaEvaluator;
. . .
my $eval = LinguaEvaluator.new();
$eval.eval($ast.made);让我提醒一下上一章中的两个设计思路。任何一个 AST 节点都是抽象的 ASTNode 类的子类, 而顶层节点包含了一个语句数组中的一切。
class ASTNode {
}
class AST::TOP is ASTNode {
has ASTNode @.statements;
}执行一个程序意味着运行所有的节点。因此, 我们从顶层开始, 把所有的语句一个个的拿出来。
use LinguaAST;
class LinguaEvaluator {
method eval(ASTNode $top) {
self.eval-node($_) for $top.statements;
}
}对于每个语句, eval-node 方法都会被调用。我们不需要显式地检查每个语句的真实性, 因为我们可以让Raku使用它的多重调度功能来决定对给定语句调用哪个方法。
让我们从最简单的程序开始, 声明一个变量并初始化它的值。
my a = 7;在 AST 中, 有一个语句是关于这个程序的。
AST::TOP.new(
statements => Array[ASTNode].new(
AST::ScalarDeclaration.new(
variable-name => "a",
value => AST::NumberValue.new(
value => 7
)
)
)
)节点的类型是 AST::ScalarDeclaration, 所以应该有一个多方法的 eval-node, 它的参数为该类型的参数。
class LinguaEvaluator {
. . .
multi method eval-node(AST::ScalarDeclaration $node) {
. . .
}
}该方法的工作是创建一个变量, 并将值放入其中。但是, 现在你把变量存储在哪里呢?在前几章中, %!var 散列是 LinguaActions 类的一部分。现在, 我们不需要它了, 可以把哈希声明从类中删除。
顺便说一下, 这是个很好的理智检查:在 LinguaActions 类中应该不会再有哈希的引用了。我们在 LinguaActions.string 方法中还剩下一个, 它是用来进行字符串插值的。让我们把它从那里删除, 并尽可能地保持动作方法的简单。
class LinguaActions {
. . .
method string($/) {
$/.make(AST::StringValue.new(value => ~$/[0]));
}
. . .
}由于类中没有剩余的数据成员, 所以我们可以摆脱实例化, 将一个类名代替实例传递给解析器。
my $ast = Lingua.parse($code, :actions(LinguaActions));如果现在一切都运行了, 那么你对 LinguaActions 类的定义就完全清理了。
9.2. 使用变量
这些变量可以存储在 LinguaEvaluator 对象内部, 我们可以将我们的数据存储添加到它的内部。
class LinguaEvaluator {
has %!var;
. . .
}使用这个散列来创建我们的第一个变量。
multi method eval-node(AST::ScalarDeclaration $node) {
%!var{$node.variable-name} =
$node.value ~~ AST::Null ?? 0 !! $node.value.value;
}计算器的所有信息都是从 AST 节点中获取的。在这种情况下, 它告诉我们它的类型( AST::ScalarDeclaration 是标量声明), 变量的名称($node.variety-name)和变量的内容($node.value)。如果没有值($node.value 属性包含 AST::Null), 让我们将 0 存储在变量中。否则, 只需复制值节点的 value 属性。
为了调试, 添加几个 dd 调用来显示 AST 和变量存储内容。
method eval(ASTNode $top) {
dd $top;
self.eval-node($_) for $top.statements;
dd %!var;
}程序执行我们的第一个例子, 成功创建并初始化了变量。
Hash %!var = {:a("7")}这都很好, 所以让程序打印出变量的值。
my a = 7;
say a;这个程序的 AST 包含两个语句。
AST::TOP.new(
statements => Array[ASTNode].new(
AST::ScalarDeclaration.new(
variable-name => "a",
value => AST::NumberValue.new(
value => 7
)
),
AST::FunctionCall.new(
function-name => "say",
value => AST::Variable.new(
variable-name => "a"
)
)
)
)第二个语句是一个 AST::FunctionCall 节点。它保留了函数的名称, 并在另一个 AST 节点中保留了引用变量的节点。
现在计算器应该为函数调用节点找到一个 multi 方法。这里是这样的。
multi method eval-node(AST::FunctionCall $node) {
self.call-function($node.function-name, $node.value);
}由于我们预期会有不止一个函数, 而且它们的参数可能是不同类型的, 所以让我们为每个函数及其参数实现另一组多方法。对于给定的程序, 我们需要一个说函数打印一个变量。
multi method call-function('say', AST::Variable $value) {
say %!var{$value.variable-name};
}这个方法完成了最后的工作:它访问变量存储并将变量打印到输出。
现在我们可以明显地看到, 如何使用 multi 方法来实现打印数字和字符串。
multi method call-function('say', AST::NumberValue $value) {
say $value.value;
}
multi method call-function('say', AST::StringValue $value) {
say $value.value;
}通过这些补充, 编译器可以处理以下程序。
my a = 7;
say a;
say 8;
say "nine";还可以做一些其他的步骤, 让其他的简单操作。我们从标量赋值开始。
a = 10;在左边有一个变量, 右边有一个 NumberValue。
AST::ScalarAssignment.new(
variable-name => "a",
rhs => AST::NumberValue.new(
value => 10
)
)该值可以通过 $.value 属性直接访问。
multi method eval-node(AST::ScalarAssignment $node) {
%!var{$node.variable-name} = $node.rhs.value;
}AST 的好处是它的节点代表了简单的操作。如变量声明或赋值等。这意味着它的实现足够简单直接。
让我们教计算器创建数组和哈希值。
my data[];
my relation{};为了实现它, 我们必须为 AST::ArrayDeclaration 和 AST::HashDeclaration 再定义几个 multi 方法。
multi method eval-node(AST::ArrayDeclaration $node) {
%!var{$node.variable-name} = Array.new;
}
multi method eval-node(AST::HashDeclaration $node) {
%!var{$node.variable-name} = Hash.new;
}执行后, 变量存储包含了所需的对象。
Hash %!var = {:data($[]), :relation(${})}我们还需要考虑数组和哈希初始化的一个赋值, 但让我们先对单元素进行处理。
data[3] = 4;
color{"red"} = "#FF0000";对数组和哈希元素的分配就是这么简单。
multi method eval-node(AST::ArrayItemAssignment $node) {
%!var{$node.variable-name}[$node.index] = $node.rhs.value;
}
multi method eval-node(AST::HashItemAssignment $node) {
%!var{$node.variable-name}{$node.key} = $node.rhs.value;
}接下来的逻辑步骤是实现数组和哈希分配。
data = 7, 8, 9;
color = "white": "#FFFFFF", "black": "#000000";编码, 这是关于两种更多的 multi 方法。
multi method eval-node(AST::ArrayAssignment $node) {
%!var{$node.variable-name} =
($node.elements.map: *.value).Array;
}
multi method eval-node(AST::HashAssignment $node) {
%!var{$node.variable-name} = Hash.new;
while $node.keys {
%!var{$node.variable-name}.{$node.keys.shift} =
$node.values.shift.value;
}
}我们还没有讲到初始化, 但你会惊讶地发现, 下面的代码已经可以用了。
my array[] = 1, 3, 4;
my h{} = "a": 1, "b": 2;这是可能的, 因为在 AST 树中, 数组和哈希声明的初始化是由相同的 AST 节点呈现的。AST::ArrayAssignment 和 AST::HashAsignment。
9.3. 字符串插值
让我们以一个带字符串插值的程序为例。
my alpha = 54;
say "The value of α is $alpha.";如果你运行它, 字符串将被按原样打印出来, 没有插值的变量。所以, 我们必须还原出这样做的代码。
问题是, AST::StringValue 只包含一个字符串本身, 如果要进行替换, 我们需要再次解析这个字符串, 找到里面提到的所有变量。这样做的效率并不高, 最好是立即将变量的信息存储在解析器中。让我们提醒一下描述字符串的语法 token。
token string {
'"' ( [
| <-["\\$]>+
| '\\"'
| '\\\\'
| '\\$'
| '$' <variable-name>
]* )
'"'
}变量名降落在匹配对象中。让我们在 AST 节点中为它们预留空间。
class AST::StringValue is ASTNode {
has Str $.value;
has @.interpolations;
}在这个动作中, 进行一些简单的计算, 计算出变量的名称及其在字符串中的位置。
method string($/) {
my $match = $/[0];
my @interpolations;
push @interpolations, [
.Str,
.from - $match.from - 1,
.pos - .from + 1,
] for $match<variable-name>;
$/.make(AST::StringValue.new(
value => ~$match,
interpolations => @interpolations
));
}最后, 在 LinguaEvaluator 类中, 可以对字符串进行处理, 以替代变量。
multi method call-function('say', AST::StringValue $value) {
say self.interpolate($value);
}
method interpolate(AST::StringValue $str) {
my $s = $str.value;
for $str.interpolations.reverse -> $var {
$s.substr-rw($var[1], $var[2]) = %!var{$var[0]};
}
$s ~~ s:g/\\\"/"/;
$s ~~ s:g/\\\\/\\/;
$s ~~ s:g/\\\$/\$/;
return $s;
}你可以对代码进行优化, 把这三个替换移到 LinguaActions 类中, 但要意识到变量插值必须在每次访问字符串时都要进行, 因为变量的值可能会在两次调用之间发生变化, 如下例所示。
my alpha = 54;
say "The value of α is $alpha.";
my beta;
beta = 200;
alpha = 100;
say "And now it is $alpha (β = $beta).";9.4. 使用 Raku getters
在上一节中, 我们创建了一个单独的方法来插值字符串中的变量。通过 say 函数进行插值, 效果很好。想象一下, 现在我们想把一个字符串分配给一个变量。
my date = 18;
my month = "October";
my year = 2018;
my date = "$date $month $year";
say date;这段代码是不行的, 因为计算器没有进行过插值。标量声明的 eval-node 方法(还有初始化也是如此)是使用 AST::StringValue 对象的 value 属性。
multi method eval-node(AST::ScalarDeclaration $node) {
%!var{$node.variable-name} =
$node.value ~~ AST::Null ??
0 !! $node.value.value;
}如果从 $node.value.value 取的字符串已经包含了一个带插值变量的字符串, 那就太好了。我们不应该静态地去做(在创建 AST::StringValue 节点的时候), 因为在使用字符串之前, 变量可能会改变它们的值。
幸运的是, Raku 提供了一种机制, 允许我们在不改变使用该值属性的代码的情况下改变其行为。事实上, 我们已经在使用一个同名的 getter 方法, value, 这个方法是 Raku 为响应类属性的声明而创建的。
class AST::StringValue . . . {
has Str $.value;
. . .
}可以用我们自己的实施方式来重新定义方法。
class AST::StringValue is ASTNode {
has Str $.value;
has @.interpolations;
method value() {
. . .
return . . . ;
}
}现在, 我们可以在 AST::StringValue 的 value 方法中调用插值代码。因为它需要访问变量存储, 所以我们将其作为参数传递给它。
class AST::StringValue is ASTNode {
has Str $.value;
has @.interpolations;
method value(%var) {
my $s = $!value;
for @!interpolations.reverse -> $var {
$s.substr-rw($var[1], $var[2]) = %var{$var[0]};
}
. . .
return $s;
}
}注意 %var 变量是如何与方法中的 $!value 和 @!interpolations 属性一起使用的。
在计算器中, 传递 %!var 存储。
multi method eval-node(AST::ScalarDeclaration $node) {
%!var{$node.variable-name} =
$node.value ~~ AST::Null ??
0 !! $node.value.value(%!var);
}另一个我们可以通过重新定义 AST 节点的 value 方法计算值的部分是访问数组和键的项目。下面的程序是一个包含这两种情况的例子。
my a[] = 10, 20;
my b{} = "A": "ey", "B": "bee";
my index = 1;
say a[index]; # prints 20
my key = "A";
say b{key}; # prints "ey"与前面的例子不同, 这里使用变量作为数组索引和散列键。
让我们允许变量自己计算它们的值。
class AST::Variable is ASTNode {
has Str $.variable-name;
has $.evaluator;
method value() {
return $.evaluator.var{$.variable-name};
}
}当你建立 AST 节点时, 将计算器的引用传递给 AST 节点。对于数组项。
multi method array-index($/ where $<variable-name>) {
$/.make(AST::Variable.new(
variable-name => ~$<variable-name>,
evaluator => $!evaluator,
));
}而对于哈希键值对:
multi method hash-index($/ where $<variable-name>) {
$/.make(AST::Variable.new(
variable-name => ~$<variable-name>,
evaluator => $!evaluator,
));
}另外, 不要忘记标量变量。例如, 当它们在表达式中使用时, 也可以返回它们的值。
multi method expr($/ where $<variable-name> && !$<index>) {
$/.make(AST::Variable.new(
variable-name => ~$<variable-name>,
evaluator => $!evaluator,
));
}9.5. 到处插值
这时, 又出现了一个问题。我们只需要对字符串进行插值, 但 eval-node 方法只是对 value(%!var) 方法进行了一个通用调用。
它在我们的测试程序中失败了, 因为三个 AST::ScalarDeclaration 节点中的两个节点包含了对数字的引用, 而不是字符串, 因此没有一个值方法可以接受哈希。如果你改变程序, 使其只使用字符串, 它就开始工作了。
my date = "18";
my month = "October";
my year = "2018";
. . .我们要想办法让代码对字符串和数字都正确, 但要保持简单。其中一个可能的解决方案是每次在取值的情况下, 检查 AST 节点的类型。另一种解决方案是定义一个方法, 在 AST::NumberValue 类中取参数。这两种方法似乎都是相当耗费行数和多余的。相反, 让我们允许 AST 节点直接访问变量。
我们将计算器对象传递给 LinguaActions 的实例, 并在节点变量中保留一个对它的引用。主程序必须稍作修改, 在实际解析之前必须先创建一些对象。
my $evaluator = LinguaEvaluator.new();
my $actions = LinguaActions.new(:evaluator($evaluator));
my $ast = Lingua.parse($code, :actions($actions));
if $ast {
say 'OK';
$evaluator.eval($ast.made);
}
else {
error('Error: parse failed');
}我们将传递一个 LinguaEvaluator 类型的计算器对象给 actions 类的构造函数。注意, 我们向 parse 方法传递了一个 LinguaActions 的实例, 而不仅仅是类名。
因为我们愿意在计算器类之外使用变量, 所以让我们通过将其 twigil 改为点来声明它是公共的。
class LinguaEvaluator {
has %.var;
. . .
}(正如我们从上一节中看到的, 在其他编程语言中会被调用的数据方法, 在 Raku 中是一个属性和 getter 方法的组合。)
在 LinguaActions 类中, 添加一个属性, 用于保存计算器。
use LinguaEvaluator;
class LinguaActions {
has LinguaEvaluator $.evaluator;
. . .
}我们要把它传给 AST 节点, 但只有在创建 AST::StringValue 节点时才会传给 AST 节点。
$/.make(AST::StringValue.new(
evaluator => $!evaluator,
value => ~$match,
interpolations => @interpolations
));其他类型的节点不需要这样的引用, 因为它们不使用计算器对象中的数据。所以, 我们只需要改变 AST::StringValue 类就可以了。
class AST::StringValue is ASTNode {
has Str $.value;
has @.interpolations;
has $.evaluator;
. . .
}在这个类中, 我们将用我们自己的方法重新定义默认 value getter, 该方法可以对变量进行插值, 从计算器的变量存储中获取变量。
method value() {
my $s = $!value;
for @!interpolations.reverse -> $var {
$s.substr-rw($var[1], $var[2]) =
$.evaluator.var{$var[0]};
}
. . .
}现在代码又可以工作了, 字符串可以成功地进行数字和字符串的插值。
9.6. 算术操作
现在是时候恢复我们在编译器内的工作了, 是时候恢复我们的计算器的工作了, 实现 AST::MathOperations 节点的解决方案了。我们之前做的工作, 重新使用 value 方法带来了它的好处, 而且代码非常简单。
class AST::MathOperations is ASTNode {
. . .
method value() {
my $result = @.operands.shift.value;
while @.operands {
$result = operation(
@.operators.shift,
$result, @.operands.shift.value);
}
return $result;
}
}实际的操作方法和我们在第三章讨论的计算器中的操作方法是一样的。把它们放到 AST::MathOperations 类中。
multi sub operation('+', $a, $b) {
$a + $b
}
multi sub operation('-', $a, $b) {
$a - $b
}
multi sub operation('*', $a, $b) {
$a * $b
}
multi sub operation('/', $a, $b) {
$a / $b
}
multi sub operation('**', $a, $b) {
$a ** $b
}完成了这些, 我们可以简化 say 函数的实现。以前, 我们有两个多变量反应 AST::NumberValue 或 AST::StringValue。由于现在字符串本身就是插值变量, 所以我们只需要取节点的值就可以了, 不需要区分节点的类型。
multi method call-function('say', ASTNode $value) {
say $value.value;
}不要忘记指定 say 函数对数组和哈希值的行为。同样, 使用正确的 where 子句的多重调度在这里也有帮助, 而条件则会变得有点拗口。
multi method call-function('say', AST::Variable $value
where %!var{$value.variable-name} ~~ Array) {
say %!var{$value.variable-name}.join(', ');
}
multi method call-function('say', AST::Variable $value
where %!var{$value.variable-name} ~~ Hash) {
my $data = %!var{$value.variable-name};
my @str;
for $data.keys.sort -> $key {
@str.push("$key: $data{$key}");
}
say @str.join(', ');
}对于数组和散列项来说, 函数很简单。
multi method call-function('say', AST::ArrayItem $item) {
say %!var{$item.variable-name}[$item.index.value];
}
multi method call-function('say', AST::HashItem $item) {
say %!var{$item.variable-name}{$item.key.value};
}本章到这里就结束了, 我们用 AST 树来计算其节点的值, 并在最后运行程序。由于我们将一些逻辑移到了 AST 节点上, 所以所建立的计算器类非常紧凑。这让我们在纯设计和代码的复杂性之间取得了很好的平衡。
10. 测试套件
编译器变得越来越大,我们要给 Lingua 语言增加更多的语法。这是一个很好的时机,让编译器的开发停顿一下,保证一些稳定性。在这一章中,我们将创建一个测试套件,这样可以让我们在扩展语言的时候发现实现中的问题,防止出现新的 bug。
Raku 的测试套件本身就是一组用 Raku 编写的文件。他们使用的测试模块与我们在第3章中所做的类似。这很好,但要运行这些测试,你需要一个能解析的编译器。对于我们的目的,这种方法是一种开销,所以让我们想出自己的解决方案。
我们的目标是测试 Lingua 的所有功能,所以我们必须为变量声明 - 包括标量、数组、散列和散列 - 赋值、不同的表达式的不同运算符、字符串插值等创建测试实例。在接下来的章节中,我们将增加条件项和函数,所以我们也要为它们创建测试。
前面几章我们都在做什么,看看编译器是否正常工作?我们看的是 AST,看变量存储的内容,以及输出的内容。这三个部分都告诉了我们编译器的健康状况。测试所有这些都是一个困难的任务。让我们限制一下自己,只检查测试程序输出的内容。语法树的结构对终端用户来说并不是那么重要,所以我们可以根据需要不时地手动检查。变量存储更重要,但我们总是可以将变量打印出来,从而将第二个任务转化为检查输出。
所以,我们最终的目标是让描述我们想要的输出的方式,并创建一个程序,运行实例并比较输出的正确值。
10.1. 测试 runner
让我们从一个简单的程序开始,创建一个变量并给它分配一个数值。我们至少有两种方法可以做到这一点。
my a;
a = 10;
my b = 20;这个程序不打印任何东西,所以我们再加上几个 say 的调用。
my a;
a = 10;
say a;
my b = 20;
say b;将测试保存在一个文件中,例如,variable-declaration.t,保存在专门的目录 t 中,然后运行它。它生成的结果与我们之前添加到编译器中的一些测试输出混合在一起(例如,一个完整的 AST 和 %!var 散列的转储)。由于我们仍然要在编译器上工作,所以让我们保留帮助器输出,但将其过滤到 /dev/null。好在 Rakudo 的 dd 例程将其输出打印到 STDERR,而不是 STDOUT。
$ ./lingua t/variable-declaration.t 2>/dev/null
OK
10
20这样看起来很干净,我们甚至可以通过使用 note 函数来省略 OK 这一行,而不是传统的 say。
if $ast {
note 'OK';
$evaluator.eval($ast.made);
}现在,所有的帮助器输出到 STDERR,程序的有效载荷通过 STDOUT 打印出来。
$ ./lingua t/variable-declaration.t 2>/dev/null
10
20这个输出,就是我们要对比的结果是正确的。最简单的方法就是把它保存在另一个文件中,只需要比较一下文件就可以了。另一种方法是在测试程序本身的注释中输入答案。为了让标准注释,也就是用户解释程序的注释,让我们介绍一下我们的特殊类型的注释,带有双哈希符号。它仍然被编译器忽略,但对测试框架来说是可见的。
my a;
a = 10;
say a; ## 10
my b = 20;
say b; ## 20现在的任务很简单。我们需要创建一个脚本,运行t目录中的所有文件,提取其中的注释,并将预期的数据与实际输出的数据进行比较。为了进一步简化任务,让我们假设测试文件都是小程序,所以如果出了问题,你可以很容易发现错误发生的行。
让我们创建另一个可执行程序,run-tests。它扫描 t 目录,并逐一运行测试。我们使用的是测试模块,在第三章中介绍过的 Test 模块。
use Test;
test-file($_) for dir('t').sort;
done-testing;运行一个单一的测试是非常简单的。下面的函数使用内置的 run 函数完成了这项工作,它将 STDOUT 和 STDERR 的输出放到返回对象的 out 和 err 属性中。
sub test-file($file) {
my $path = $file.path;
my $proc = run('./lingua', $path, :out, :err);
is(expected($path), $proc.out.slurp, $path);
}输出中的转义序列会添加颜色,这样你可以立即看到红色的 FAIL`s 或绿色的 `OK。
测试失败有两种可能:要么文件没有被解析,要么生成的输出与期望值不同。预期的输出字符串是从 ## 注释中提取出来的。
sub expected($path) {
my $expected;
for $path.IO.lines -> $line {
$line ~~ /'##'\s*(\N*)/;
next unless $0;
$expected ~= "$0\n";
}
return $expected;
}运行程序,你应该会看到下面的输出。
ok 1 - t/array-creation.t
ok 2 - t/expressions.t
ok 3 - t/expressions2.t
ok 4 - t/hash-creation.t
ok 5 - t/hashes.t
ok 6 - t/numbers.t
ok 7 - t/print.t
ok 8 - t/string-escaping.t
ok 9 - t/string-index.t
ok 10 - t/string-interpolation.t
ok 11 - t/string.t
ok 12 - t/variable-as-index.t
ok 13 - t/variable-declaration.t
1..13现在,我们可以添加更多的测试来覆盖 Lingua 的更多功能。
10.2. 测试
准备好了测试运行程序后,是时候在 t 目录中填充许多具有语言不同方面特征的文件了。其中一个测试文件,variable-declaration.t 已经在那里了。
10.2.1. 数字
以不同格式创建数字。
my int = 42;
say int; ## 42
my float = 3.14;
say float; ## 3.14
my sci = 3E14;
say sci; ## 300000000000000
my negative = -1.2;
say negative; ## -1.2
my zero = 0;
say zero; ## 0
my half = .5;
say half; ## 0.5
my minus_n = -.3;
say minus_n; ## -0.3请注意,没有整数部分的浮点数字在小数点前以0打印,因此你应该期望 0.5 而不是 .5。
10.2.2. 字符串
对于字符串,我们先来测试一下简单的初始化和赋值。
my s1;
s1 = "Hello, World!";
say s1; ## Hello, World!
my s2 = "Another string";
say s2; ## Another string
my s3 = ""; # Empty string
say s3; ##在另外一个文件中,让我们测试一下字符串插值。
my i = 10;
my f = -1.2;
my c = 1E-2;
my s = "word";
my str = "i=$i, f=$f, c=$c, s=$s";
say str; ## i=10, f=-1.2, c=0.01, s=word我们还允许转义三个字符(\、" 和 $)。
say "\\"; ## \
say "\\\\"; ## \\
say "\$"; ## $
say "\""; ## "10.2.3. 表达式
我们在第三章中已经看到了很多不同的算术表达式的测试。把它们收集在一起,连同答案一起放到 t/expression.t 中(或者最好是两三个不同的文件中)。我们应该按照不同的顺序来测试这五个运算符,这样我们就可以检查优先级和括号。
10.2.4. 数组和散列
聚类数据类型对于语言来说是非常重要的,所以我们也来测试一下。首先是一些创建和打印数组的一些琐碎的测试用例。
my a[];
a = 3, 4, 5;
say a; ## 3, 4, 5
my b[] = 7, 8, 9;
say b; ## 7, 8, 9还有散列。
my h{};
say h; ##
my g{} = "a": "b", "c": "d";
say g; ## a: b, c: d然后尝试使用变量作为数组索引或散列键。
my a[] = 2, 4, 6, 8, 10;
my i = 3;
say a[i]; ## 8
my b{} = "a": 1, "b": 2;
my j = "b";
say b{j}; ## 2这个测试的效果很好。
10.2.5. 发现错误
上面的测试都通过了,但是让我们试试简单的字符串索引。
not ok 17 - t/string-index.t
# Failed test 't/string-index.t'
# at ./run-tests line 14
# expected: 'a
# d
# f
# '
# got: 'abcdef'我们不打印单个字符,而是打印整个字符串(而且只打印一次)。让我们修改一下程序,让它在测试失败时打印出错误。
is(expected($path), $proc.out.slurp, $path)
or say $proc.err.slurp;在错误信息中,你会看到一些来自于 Raku 的解释。
# Index out of range. Is: 3, should be in 0..0我们把索引拧了,不是没有正确保存在 AST 节点中,就是后来没有使用。下面是前两个打印指令对应的树的片段。
AST::FunctionCall.new(
function-name => "say",
value => AST::ArrayItem.new(
variable-name => "abc",
index => AST::NumberValue.new(
value => 0
)
)
),
AST::FunctionCall.new(
function-name => "say",
value => AST::ArrayItem.new(
variable-name => "abc",
index => AST::NumberValue.new(
value => 3
)
)
),第一个假设没有得到证实,因为我们看到索引是存储在 AST 节点的相应属性中的。让我们切换到计算器,看看那里的值是如何使用的。我们的候选者是一个取数组项的多方法。
multi method call-function('say', AST::ArrayItem $item) {
say %!var{$item.variable-name}[$item.index.value];
}解析器将代码理解为数组索引,而 call-function 方法将字符串视为数组。当索引为0的时候就可以了,因为在 Raku 中,你总是可以"索引"一个标量值。
$ raku
To exit type 'exit' or '^D'
> my $x = 10;
10
> say $x[0];
10如果索引为非零,就会弹出上述的错误。
> say $x[3];
Index out of range. Is: 3, should be in 0..0
in block <unit> at <unknown file> line 1确实,有一个表达式 abc[3],你怎么知道变量 abc 是数组还是字符串?为了让语言更干净,我们去掉了任何 sigil,但现在如果能把它们找回来就好了。有了 sigil,区分 $abc 和 @abc 就更容易了。你可以更进一步,使用某种匈牙利语符号来让编译器知道变量的类型。比如说,$s_abc 只存储字符串,而 $i_abc 只存储整数。虽然这样做对编译器有帮助,但对终端用户来说,这样做会让语言变得更重。
让我们在运行时要求计算机检查变量的类型。我们已经为多函数的替代变量做了。下面是只处理字符串的更新版本。
multi method call-function('say', AST::ArrayItem $item
where %!var{$item.variable-name} ~~ Str) {
say %!var{$item.variable-name}.substr($item.index.value, 1);
}运行测试套件,你会确认测试通过了。不幸的是,另一个测试,t/variable-as-index.t,发生故障了。
这个例子展示了测试的帮助。如果没有测试,你可以在编译器中改变一些东西,而不注意到其他的东西开始错误地工作。幸运的是,我们很快就发现了这个问题,解决的方法就是返回之前修改过的多方法,覆盖了缺失的代码。
multi method call-function('say', AST::ArrayItem $item
where %!var{$item.variable-name} ~~ Array) {
say %!var{$item.variable-name}[$item.index.value];
}测试套件现在报告的都很好。
10.3. 功能覆盖
重要的是,要为语言的每一个特性,并为尽可能多的潜在用例创建测试。例如,我们测试了简单的标量赋值,比如 i = 10,但没有尝试让数组项在方程的右侧有一个数组项。
my a[] = 3, 5, 7;
my x = a[1];
say x;出乎意料的是,这并没有起到任何作用,并产生错误信息。
No such method 'value' for invocant of type 'AST::ArrayItem'.
Did you mean 'values'?
in method eval-node at /Users/ash/lingua/LinguaEvaluator.rakumod
(LinguaEvaluator) line 17
in method eval at /Users/ash/lingua/LinguaEvaluator.rakumod
(LinguaEvaluator) line 9
in block <unit> at ./lingua line 21问题就出在了赋值的行上。AST 树的建立是正确的。
. . .
AST::ScalarDeclaration.new(
variable-name => "x",
value => AST::ArrayItem.new(
variable-name => "a",
index => AST::NumberValue.new(
value => 1
)
)
),
. . .让我们检查一下计算器(顺便说一下,错误信息中明确提到了它)。
multi method eval-node(AST::ScalarDeclaration $node) {
%!var{$node.variable-name} =
$node.value ~~ AST::Null ?? 0 !! $node.value.value;
}这里一切都很好,但是我们没有 AST::ArrayItem 节点的值,因此我们必须实现它。
class AST::ArrayItem is ASTNode {
has Str $.variable-name;
has ASTNode $.index;
has $.evaluator;
method value() {
return $.evaluator.var{$!variable-name}[$!index.value];
}
}你可能也注意到我们在 AST::HashItem 类中没有这样的方法。把它也加入进来。
class AST::HashItem is ASTNode {
has Str $.variable-name;
has ASTNode $.key;
has $.evaluator;
method value() {
return $.evaluator.var{$!variable-name}{$!key.value};
}
}在动作类中构建 AST 节点时,不要忘记传递一个计算器(在 LinguaActions.rakumod 文件中不止一个地方)。
$/.make(AST::ArrayItem.new(
. . .
evaluator => $!evaluator,
));
. . .
$/.make(AST::HashItem.new(
. . .
evaluator => $!evaluator,
));我们应该为数组和散列数都添加测试。
my g{} = "a": "b", "c": "d";
say g{"a"}; ## b
my x = g{"a"};
say x; ## b就这样(几乎)结束了这一章。所有的测试都通过了!
10.3.1. 这永远是不够的
在进行下一步之前,让我们先把前面介绍的一个小要素解决掉。考虑一下下面的赋值与表达式。
my x = 10;
my y = 2 * x;
my z = x * 2;
say "$x, $y, $z";分配给 y 和 z 的值应该没有区别,但 parse 方法拒绝接受第二个表达式 x*2。这种情况发生在语法中一个变量被控制的地方。
rule value {
| <variable-name> <index>?
| <expression>
| <string>
}其实,既然我们现在有了 AST,那么让变量成为表达式的一部分就可以了,我们可以放心地去掉那个备选。
rule value {
| <expression>
| <string>
}这个小改动恢复了解析器,2*x 和 x*2,以及 x*x 现在都可以解析了。
在这种情况下,不仅要修复语法、动作或计算器,还需要建立一个回归测试,避免将来出现同样的 bug。
my x = 10;
my y = 2 * x;
my z = x * 2;
my q = x * x;
my d = 2 * 2;
say "$x, $y, $z"; ## 10, 20, 20
say "$q, $d"; ## 100, 411. 控制流
我们在第8章开始时,尝试实现了 if 关键字。在逐行执行代码的解释器中,这样做是很棘手的。引入 AST 允许在不执行程序的情况下解析程序,所以我们可以先建立节点,只有在条件为真的情况下,才会运行它后面的代码。
11.1. 实现 if
我们首先要实现的语言结构是前缀 if 子句,在下面的例子中演示:
my flag = 42;
if flag say "Depends";
say "Always";if 关键字后面是一个值(也就是条件)和一个语句。值是我们 grammar 意义上的 value,因此它可以是一个变量,也可以是一个字符串,或者是一个表达式。语句可以是 statement 规则所认可的任何构造。
将 if 子句嵌入到 grammar 中很简单,因为我们将所有的 statement 定义都包含在一条规则中:
rule condition {
'if' <value>
}
rule statement {
<condition> ? [
| <statement=variable-declaration>
| <statement=assignment>
| <statement=function-call>
]
}前面我们已经看到,在知道条件是否为真之前,我们不应该执行语句。在 AST 的世界里,我们可以从树上挑出语句节点,把它放到条件节点的属性上。之后,计算器决定是否执行该语句节点。所以,我们需要一种新的 AST 节点:
class AST::Condition is ASTNode {
has ASTNode $.value;
has ASTNode $.statement;
}在 action 类中,响应于解析的语句而触发的方法现在应该被分成两个分支。当没有 if 子句时,一切都保持原样。当有这样一个子句时,语句节点通过代理 AST::Condition 节点进入树中:
multi method statement($/ where !$<condition>) {
$/.make($<statement>.made);
}
multi method statement($/ where $<condition>) {
$/.make(AST::Condition.new(
value => $/<condition><value>.made,
statement => $/<statement>.made,
));
}测试程序的整个 AST 绘制如下:
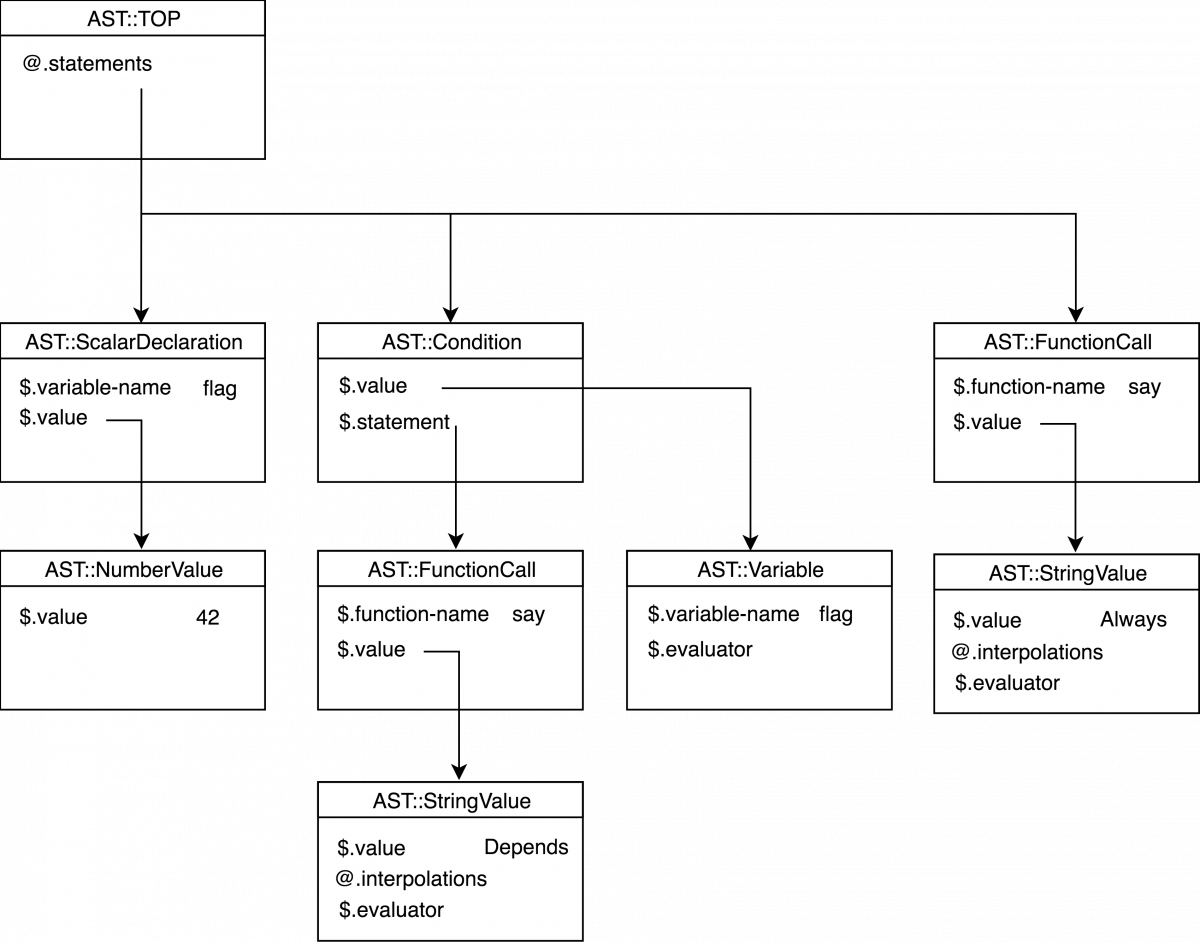
看一下 say 的两个调用。第一个调用是 AST::Condition 节点的子节点。第二个(图中的右侧)位于 TOP 的 @.statement 数组里面的顶层。
这个树已经准备好了,我们可以对它进行计算了。LinguaEvaluator 类需要一种方法来响应 AST::Condition 类型的 AST 节点。If 应该检查条件值,并在需要时进一步传递执行。
multi method eval-node(AST::Condition $node) {
if $node.value.value {
self.eval-node($node.statement);
}
}就这些了! 用标志变量的不同值来测试程序,看看程序的反应如何。
为了完成实现,在 t 目录下添加一个测试:
my flag = 1;
if flag say "Printed"; ## Printed
flag = 0;
if flag say "Ignored";
say "Done"; ## Done11.2. 实现 else
合乎逻辑的下一步是实现 else 子句。让我们扩展一下测试程序:
my flag = 0;
if flag say "Depends" else say "Otherwise";
say "Always";else 关键字只能在之前有一个 if 的情况下出现。在我们目前的 grammar 中,在语句后添加 else 块是很棘手的。最好的办法是重新组织 grammar,使 statement 规则只包含不同的语句变体。
让我们在顶层允许使用 if-else 构造:
rule TOP {
[
| <one-line-comment>
| <statement=conditional-statement> ';'
| <statement> ';'
]*
}
rule conditional-statement {
'if' <value> <statement>
[
'else' <statement>
]?
}
rule statement {
| <statement=variable-declaration>
| <statement=assignment>
| <statement=function-call>
}请注意,在 TOP 规则中,新的备选项被赋予了一个别名,statement,这让我们在相应的 action 中保持相同的循环:
method TOP($/) {
. . .
for $<statement> -> $statement {
$top.statements.push($statement.made);
}
. . .
}好了,我们现在可以在条件构造中拥有一个或两个语句了。AST::Conditional 节点得到第二个属性:
class AST::Condition is ASTNode {
has ASTNode $.value;
has ASTNode $.statement;
has ASTNode $.antistatement;
}新的属性用 AST::Null(如果没有 else 子句)或者用 AST::Statement 节点来填充:
method conditional-statement($/) {
$/.make(AST::Condition.new(
value => $/<value>.made,
statement => $/<statement>[0].made,
antistatement => $/<statement>[1] ??
$/<statement>[1].made !! AST::Null,
));
}statement action 现在可以还原为单一的方法,并有一个琐碎的主体:
method statement($/) {
$/.make($<statement>.made);
}最后,计算器必须决定执行哪条语句:
multi method eval-node(AST::Condition $node) {
if $node.value.value {
self.eval-node($node.statement);
}
else {
self.eval-node($node.antistatement);
}
}我们也要实现 AST::Null 节点的不操作行为:
multi method eval-node(AST::Null) {
}else 关键字已经准备好了,并开始运行,必须在仓库中加入一个测试 t/else.t:
if 1 say "A" else say "B"; ## A
if 0 say "A" else say "B"; ## B
my x;
if 1 x = 10 else x = 20;
say x; ## 10
if 0 x = 30 else x = 40;
say x; ## 4011.3. 实现循环
让我们在 Lingua 语言中实现一个循环。目前,让我们把它简单化,只允许使用 loop 关键字,并允许编译器对 counter 变量进行递减。
my n = 5;
loop n say n;这个程序会打印出从5到1的值,然后停止。
loop 子句的语法与我们在本章中看到的 if 条件类似,也可以嵌入到 grammar 的顶层:
rule TOP {
[
| <one-line-comment>
| <statement=conditional-statement> ';'
| <statement=loopped-statement> ';'
| <statement> ';'
]*
}
rule loopped-statement {
'loop' <variable-name> <statement>
}接下来,我们需要一个新的 AST 节点类型:
class AST::Loop is ASTNode {
has ASTNode $.variable;
has ASTNode $.statement;
}语法的选择方式是这样的,所以你必须为循环提供一个已经存在的变量。在这种情况下,我们不需要创建一个临时循环变量。在 action 方法中,变量的引用被保存在 AST::Variable 节点中:
method loopped-statement($/) {
$/.make(AST::Loop.new(
variable => AST::Variable.new(
variable-name => ~$/<variable-name>
),
statement => $/<statement>.made,
));
}自减计数器是在计算器中进行的:
multi method eval-node(AST::Loop $node) {
while %!var{$node.variable.variable-name} {
self.eval-node($node.statement);
%!var{$node.variable.variable-name}--;
}
}稍微重写一下停止条件,可能会更安全:
while %!var{$node.variable.variable-name} > 0 {
. . .例如,当初始值不是整数时,可以避免无限循环:
my n = 5.5;
loop n say n;让我们把成就保存在测试套件中。由于循环打印了几行,所以应该把它们全部添加到测试文件中:
my n = 3;
loop n say n;
## 3
## 2
## 111.3.1. 语句块
直到现在,if 和 else 构造都只能包含一条语句。当然,如果你需要不止一条,你总是可以在每条语句中添加一个 if 子句,但如果能实现对代码块的支持,那就更好了,这在很多其他语言中都有。本节的目标是用 if-else 和 loop 两个代码块来指导执行下面的程序:
my c = 0;
if c {
say "c = $c";
say "IF block";
}
else {
say "c = $c";
say "ELSE block";
}
my n = 5;
loop n {
say n;
say 2 * n;
}让我们第一次尝试用一个新定义的 block 来替换 statement。如果块中包含一条指令,那么花括号是可选的:
rule block {
| '{' ~ '}' <statement>* %% ';'
| <statement> ';'
}Raku中的 '{' ~ '}' <X> 构造相当于 '{' <X> '}',但它往往看起来更干净,特别是当 X 是由一大块代码代表的时候。
从概念层面上看,我们必须允许 grammar 中允许语句的代码块。从实际的角度来说,我们要考虑到语句末尾的分号。
例如,在 else 关键字之前不允许使用分号:
if 1 say "A"; else say "B";问题是,它还是站在 grammar 中的语句之后。所以,我们应该区分 if 分句中的语句有无 else 分句。
另外,我们不应该坚持在结尾花括号后加分号:
loop n {
say n;
say 2 * n;
};最后,在结尾括号前加一个分号,可以声明为可选:
loop n {
say n;
say 2 * n
}为了满足上面列出的所有条件,让我们告诉 grammar 中哪里需要分号,哪里不需要分号。我们可以引入两个 block 规则的多义词规则(记得我们在 grammar 中为计算器的方法添加参数的时候,我们是如何添加参数的吗)。
multi rule block() {
| '{' ~ '}' <statement>* %% ';'
| <statement>
}
multi rule block(';') {
| '{' ~ '}' <statement>* %% ';'
| <statement> ';'
}通过这样做,我们不增加一个新的规则名称。现在,我们可以重写条件规则,并初步引入 while 循环(我们将在本章末尾返回):
rule conditional-statement {
| 'if' <value> <block()> 'else' <block(';')>
| 'if' <value> <block(';')>
}
rule loopped-statement {
'while' <variable-name> <block(';')>
}注意,在 conditional-statement 规则中,也可以用方括号来提取共性部分:
rule conditional-statement {
'if' <value> [
| <block()> 'else' <block(';')>
| <block(';')>
]
}你可以选择二者中的一个;我个人倾向于使用两个分支相继出现的形式:
| 'if' <value> <block()> 'else' <block(';')>
| 'if' <value> <block(';')>最后,调整 TOP 规则,将其中多余的分号去掉:
rule TOP {
[
| <one-line-comment>
| <statement=conditional-statement>
| <statement=loopped-statement>
| <statement> ';'
]*
}现在说到 action 部分。首先,让我们改变条件构造的 action,在那里使用块:
method conditional-statement($/) {
$/.make(AST::Condition.new(
value => $/<value>.made,
statement => $/<block>[0]<statement>[0].made,
antistatement => $/<block>[1] ??
$/<block>[1]<statement>[0].made !! AST::Null,
));
}
method loopped-statement($/) {
$/.make(AST::Loop.new(
variable => AST::Variable.new(
variable-name => ~$/<variable-name>
),
statement => $/<block><statement>[0].made,
));
}虽然结果中包含了匹配对象的键和索引的长链,如 $/<block>[1]<statement>[0] 等,但转换过程简单易懂。你可以对程序进行测试,它将执行每个花括号块中的第一个语句。
下一步就是修改 AST,让它保留一个以上的语句,凡是允许一个块的地方,都可以保留一个以上的语句。我们必须要保留所有的语句,所以让我们用数组来代替标量:
class AST::Condition is ASTNode {
has ASTNode $.value;
has ASTNode @.statements;
has ASTNode @.antistatements;
}
class AST::Loop is ASTNode {
has ASTNode $.variable;
has ASTNode @.statements;
}相应的动作应该是创建新的 AST 节点,并将所有的语句从代码块中传递过来。在接下来的片段中,我们使用 map 来循环这些语句:
method conditional-statement($/) {
$/.make(AST::Condition.new(
value => $/<value>.made,
statements => ($/<block>[0]<statement>.map: *.made),
antistatements => $/<block>[1] ??
($/<block>[1]<statement>.map: *.made) !! (AST::Null),
));
}
method loopped-statement($/) {
$/.make(AST::Loop.new(
variable => AST::Variable.new(
variable-name => ~$/<variable-name>
),
statements => ($/<block><statement>.map: *.made),
));
}11.3.2. AST 中的块儿
OK,我们可以返回到 AST 中,当看到花括号中的块时,我们可以让节点保留语句数组。
让我们仔细看一下上面的例子中的循环:
loop n {
say n;
say 2 * n;
}在 AST 的形式下,这个片段的形状如下:
AST::Loop.new(
variable => AST::Variable.new(
. . .
),
statements => Array[ASTNode].new(
AST::FunctionCall.new(
. . .
),
AST::FunctionCall.new(
. . .
)
)
)再次,抽象语法树的抽象性在这里得到了证明。虽然我们在语法中加入了 block 规则,但在树中没有任何痕迹。这两个 say 调用立即作为 statements 数组属性的元素出现在 AST::Loop 节点内的 statements 数组属性中。
我们需要的是对计算器中的语句进行循环:
multi method eval-node(AST::Condition $node) {
if $node.value.value {
self.eval-node($_) for $node.statements;
}
else {
self.eval-node($_) for $node.antistatements;
}
}
multi method eval-node(AST::Loop $node) {
while %!var{$node.variable.variable-name} > 0 {
self.eval-node($_) for $node.statements;
%!var{$node.variable.variable-name}--;
}
}就是这样! 引入 { } 块是一个相对简单的任务。
11.3.3. 一个现实生活中的测试
如果你运行这个循环,你很快就会看到一个错误:
5
10
4
Cannot shift from an empty Array[ASTNode]
in method value at /Users/ash/lingua/LinguaAST.rakumod
(LinguaAST) line 112前三行显示的是预期的开始结果,但随后,一切突然停止了。从错误信息中可以了解到,这是因为我们在计算表达式时使用了 shift,所以才会出现这种情况。在循环中,表达式是可以重复使用的,所以我们不应该改变它们。让我们把所有的 shift 改成循环。在我们的代码中,有两个这样的地方。第一个是在 AST::MathOperations 类中:
method value() {
my $result = @.operands[0].value;
for 1 .. @.operands.elems - 1 -> $i {
$result = operation(@.operators[$i - 1],
$result, @.operands[$i].value);
}
return $result;
}第二个是计算器的 multi 方法中的一个:
multi method eval-node(AST::HashAssignment $node) {
%!var{$node.variable-name} = Hash.new;
for 0 .. $node.keys.elems - 1 -> $i {
%!var{$node.variable-name}.{$node.keys[$i]} =
$node.values[$i].value;
}
}测试代码现在可以用了。让我们用类似的指令来修复测试中的行为:
my n = 5;
loop n {
my n2 = n * n;
say "n = $n, n2 = $n2";
}
## n = 5, n2 = 25
## n = 4, n2 = 16
## n = 3, n2 = 9
## n = 2, n2 = 4
## n = 1, n2 = 1不要忘记测试 if 和 else 块。程序应该能够执行其中的所有语句。
11.3.4. 条件运算符
到目前为止,if 子句只能检查值是否为 0。让我们把它变得更强大,允许条件运算符和布尔运算符:
| & < <= > >= == !=在这里我们不介绍布尔数据类型,而是在现有的表达式中加入运算符。它使得 3+n 和 x<y 都是有效的表达式,可以作为 if 测试中的条件。
以上列出的运算符都是二元运算符,其优先级低于算术运算符 + 和 -。其中,& 的优先级较高。所以,我们必须更新 grammar 中的运算符,并添加新的运算符:
multi token op(1) {
| '|'
| '<' | '>'
| '<=' | '>='
| '==' | '!='
}
multi token op(2) {
'&'
}更新其余的部分,明确给予优先级:
multi token op(3) {
'+' | '-'
}
multi token op(4) {
'*' | '/'
}
multi token op(5) {
'**'
}
multi rule expr(6) {
| <number>
| <variable-name> <index>?
| '(' <expression> ')'
}将函数添加到 AST::MathOperations 类中:
multi sub operation('|', $a, $b) {
$a || $b
}
multi sub operation('&', $a, $b) {
$a && $b
}
multi sub operation('<', $a, $b) {
$a < $b
}
multi sub operation('<=', $a, $b) {
$a <= $b
}
multi sub operation('>', $a, $b) {
$a > $b
}
multi sub operation('>=', $a, $b) {
$a >= $b
}
multi sub operation('!=', $a, $b) {
$a != $b
}
multi sub operation('==', $a, $b) {
$a == $b
}我们在这里依靠 Raku 的运算符。另一种选择是只产生1或0,比如说:
multi sub operation('<', $a, $b) {
$a < $b ?? 1 !! 0
}在测试中,尝试不同的运算符及其组合:
my x = 10;
my y = 20;
if x > y say ">" else say "<"; ## <
if x < y say ">" else say "<"; ## >
if x != y say "!=" else say "=="; ## !=
if x != x say "!=" else say "=="; ## ==
if x == y say "==" else say "!="; ## !=
if x == x say "==" else say "!="; ## ==
if 5 <= 5 say "5 <= 5"; ## 5 <= 5
if 5 <= 6 say "5 <= 6"; ## 5 <= 6
if 5 >= 5 say "5 >= 5"; ## 5 >= 5
if 6 >= 5 say "6 >= 5"; ## 6 >= 5
if (10 > 1) & (5 < 50) say "OK 1"; ## OK 1
if (10 < 1) | (5 < 50) say "OK 2"; ## OK 211.4. 实现 while 循环
在本章结束之前,让我们先来实现一下 while 关键字,下面的代码说明了这一点:
my n = 1;
while n <= 5 {
say n;
n = n + 1
}循环体被运行,直到条件停止为真为止。
从语法和语义上看,while 循环与我们之前的 loop 循环非常接近。实现它主要是一个复制粘贴的工作。
在 grammar 中:
rule TOP {
[
. . .
| <statement=loopped-statement>
| <statement=while-statement>
. . .
]*
}
rule while-statement {
'while' <value> <block(';')>
}定义了一个新的 AST 节点:
class AST::While is ASTNode {
has ASTNode $.value;
has ASTNode @.statements;
}在 action 中:
method while-statement($/) {
$/.make(AST::While.new(
value => $/<value>.made,
statements => ($/<block><statement>.map: *.made),
));
}在计算器中:
multi method eval-node(AST::While $node) {
while $node.value.value {
self.eval-node($_) for $node.statements;
}
}实现了 while 构造。增加一个测试,然后转入下一章。
my n = 1;
while n <= 5 {
say n;
n = n + 1
}
## 1
## 2
## 3
## 4
## 5
my k = 1;
while k < 10 k = k + 1;
say k; ## 10